


Applications without Copilots are now legacy! I have now made this statement on a number of occasions, and it's become somewhat of a battle-cry within the CODE organization. Some might find the statement a bit strong or premature, but I feel that as we push forward, this is indeed how we have to approach software development from now on.
How did we get here? Just a few months ago it seems that statements like this would not only have been preposterous, but nobody would have even known what I'm talking about. Then, OpenAI released ChatGPT at the end of November 2022 and GPT-4 in March of 2023. These artificial intelligence (AI) products not only took most of the tech world by surprise, but they captured the imagination of people who normally don't take an interest in software products. All of a sudden, I'd go to a BBQ with people who had no connection to the software industry, and all they would want to talk to me about is artificial intelligence! I've explained generative AI to retired people, hairdressers, and journalists. I've held executive briefings showing some of America's largest companies how this technology can elevate what they are doing. It seems to not matter how technical a person is; everyone is fascinated by AI (and at times, also a little afraid).
I haven't seen anything like this since the earlier days of the internet, except this happened much faster. Much faster! In fact, ChatGPT is the fastest adopted product of all times (at least outside of China) gaining millions of users in a matter of days. Yet one can argue whether it's even a “product” or whether it's “just a tech demo.” Perhaps the truth lies somewhere in between.
Whatever the case may be, one thing is clear: ChatGPT as a product is not the grand vision. Instead, the technology of what powers ChatGPT - the large language models (LLMs) that OpenAI created - are the basis for a completely new generation of software that, for the first time in any modern developer's career, completely changes how we write programs and interact with computers. We move from a model of clear and unambiguous instructions that we code into software and that results in very predictable and meticulously orchestrated results, to a fuzzier, but orders of magnitude, more powerful paradigm. We now interact with software much more like we would interact with a human. The interaction is rich and powerful, but also, at times, somewhat unpredictable.
Many Copilot/AI features in modern applications would have been considered science fiction just a few months ago.
It isn't just my friends and neighbors who got inspired by this rapid new development. Microsoft is invested in OpenAI and has to be given a lot of credit for seeing the potential in LLMs. Microsoft is the first company to use this new paradigm and places LLMs at the base of pretty much any upcoming Microsoft product, whether you are an Office user, or whether you are a system administrator concerned with security, or anything in between. For instance, you'll be able to use AI built into Microsoft Teams to provide you with a summary of a meeting you missed. You can then have the same AI create a to-do list based on the decisions made in that meeting. You can also have that UI create a PowerPoint presentation or a Word document based on what was discussed. Perhaps if one of the discussion points was that a new low-code application needs to be created, you can have the AI create a Power Platform application that satisfies the criteria. And most of the time, the AI will be able to do it better than most human users. And if not, then you either interfere by hand or ask the AI to change something. You can do all of that in plain English or any other language of your choice.
We refer to this approach as an AI “Copilot.” The AI is not autonomous. The AI does not take over. But it's always there to assist you and do what you want, even if you're not a programmer or don't even express yourself particularly well or accurately. Welcome to the Age of Copilot! This may sound like science fiction, and half a year ago it would have been, but this is now a concrete reality.
Copilots are not only for Microsoft applications. Copilots are a new application paradigm (just like Windows was once a new paradigm over command line interfaces or the web was a new paradigm over desktop apps). It's hard to imagine an application that can't benefit from the Copilot paradigm. Having built a number of business applications with Copilot features, I can testify to the enormous productivity increase this provides. (Even though we are arguably just scratching the surface.) Applications supporting this new paradigm have a considerable benefit over apps that don't. Conversely, applications that do not have such features, even if they're dominant players in their market segments today, will find themselves leapfrogged and made obsolete. It's an enormous opportunity but can be a great danger for those who “miss the boat.”
It's an enormous opportunity but can be a great danger for those who “miss the boat.”
And that's why we consider applications without Copilot features to be legacy applications. The good news is that it's often not all that hard to add Copilot features to existing applications (unlike previous paradigm shifts, where we had to abandon DOS-based apps when we moved to Windows, and then abandoned them again when we moved to the Web, and then do it all over again for Mobile apps). In this article, I aim to explain some of the basics that are required to engage in this journey as a developer. Just like Windows development couldn't be explained in a single article to a mainframe developer, I won't be able to explain this type of AI-driven development in a single article. However, I hope to at least give you a solid start.
I also invite you to check out many of the other resources we make available, such as our free State of .NET and CODE Presents webinars, our training videos and classes, CODE Executive Briefings (www.codemag.com/ExecutiveBriefing), as well as our blog on www.codemag.com/blog, which all cover many of these topics. And feel free to email me (or CODE in general: info@codemag.com).
It all starts with understanding OpenAI.
Getting Started with (Azure) OpenAI
In the July/August 2023 issue of CODE Magazine, Sahil Malik and Wei-Meng Lee both wrote articles explaining the fundamentals of OpenAI's large language models (LLMs) and even showed how to write your own code to call these AI models. Today, I'll take this a step further. But before we can run, we need to walk, so let's start with a fundamental example.
OpenAI's LLMs are currently the most talked about and accessible, and for good reason. (There are others, and we expect this to become a large ecosystem of competing and cooperating LLMs). The OpenAI models are very powerful and enable impressive scenarios. One of them is their own implementation at https://chat.openai.com, which is what people generally refer to as “ChatGPT.” I like to think of that site mainly as a tech-demo for this powerful new development paradigm. (Which isn't entirely accurate, as OpenAI is developing it into more and more of an extensible platform in its own right). Behind this chatbot interface sit OpenAI services, which provide a list of multiple individual LLMs that all have their own strengths and weaknesses. We can use those in our own applications as well.
There are two fundamental ways to call OpenAI services. One is through OpenAI directly (which is what Sahil and Wei-Meng showed in their articles), and the other is through Microsoft's version called “Azure OpenAI.” The two approaches are very similar (and the code practically identical), so why choose one over the other? That's an excellent question and perhaps the answer isn't entirely clear at this point. You can use both approaches and follow the examples in this article very closely. For instance, if you sign up for OpenAI directly (which you can do on https://platform.openai.com), you can then explore the APIs, sign up for a subscription (yes, this costs money, but not very much; you can fiddle with it for quite a while and probably spend less than a dollar), play with examples, or write code like the following Python example:
import os
import openai
openai.api_type = "open_ai"
openai.api_base = "https://api.openai.com/v1";
openai.api_version = ""
openai.api_key = "<YOUR API KEY>"
os.environ["OPENAI_API_KEY"] = openai.api_key
response = openai.Completion.create(engine="text-davinci-003", prompt="Please tell me a story.",)
print(response.choices[0].text)
This example is straightforward. It pulls in an “openai” client package, which then gets configured to access the OpenAI API subscription (make sure you put in your own API key). The most important part is the call to “openai.Completion.create().” The completions API allows you to send some text to the model and ask it to “complete it.” In other words, you send it a prompt and ask it to respond. Everything you do with LLMs revolves around “completing text,” whether it's a simple completion as in this example, or whether it's a series of back-and-forth completions, which you then perceive as a chat or a dialog. You could also ask the AI to return different versions of a completion, which are called “choices,” but in most scenarios, you just want a single version, hence we can simply retrieve the first (and only) choice.
It's OpenAI's job to train models. It's Microsoft's job to integrate AI with all kinds of other services, such as databases and security. That's why I like using Azure OpenAI.
This example could be used almost unchanged running against Azure OpenAI. You'd simply change the API type to access Azure and point the base URL at the Azure resource you want to use (see below). No further code change is required. I like using Azure OpenAI. If you already have an Azure OpenAI account, you can simply add an OpenAI resource the same exact way as you would create any other Azure resource (such as a web app or a database). One of the benefits through Azure is that you will be billed as part of your overall Azure invoice. I find that, especially for serious usages and enterprise scenarios, it's nice to have everything available and manageable in one place.
Another difference between Azure OpenAI and direct OpenAI is that the OpenAI organization is a provider of AI models, while Microsoft is a provider of many different Cloud services that form a coherent whole. It isn't OpenAI's purpose or job to integrate their AI models with other things, such as security, other cognitive services, search, databases, or many other things. OpenAI focuses entirely on creating and evolving AI. Microsoft's purpose, on the other hand, is to not worry about those details, but to provide a large platform, of which one puzzle piece is LLMs. The difference may not be immediately apparent, but we're now starting to see more and more integration across Azure offerings. For instance, we'll see, later in this article, that, through Azure, it's possible to directly integrate things like Azure Cognitive Search, Blob Storage, and more, into the use of LLMs.
On a sidenote: The first question almost every customer asks me when it comes to incorporating LLMs into their own systems is whether their data is secure. After all, if you just type a question into chat.openai.com, whatever you type in is not kept private. Instead, it's used to further train OpenAI's models. (Remember: It's OpenAI's main purpose to push the development of better and better AI models). OpenAI states that this is not the case for their paid offerings (a statement I personally trust) but it's apparent that businesses trust Microsoft more (after all, they would have much to lose and little to gain by not keeping customer data secure and private). Microsoft guarantees that data won't be used for training (or anything else). Many businesses are already comfortable putting SQL Server (and many other forms of data) into the Azure Cloud, and this equation essentially remains the same if you use Azure's OpenAI services.
Using Azure OpenAI, your data remains secure and private.
Assuming that you want to go the Azure route, you can set up an Azure OpenAI resource and run the previous Python example unchanged, once you point it to the Azure URLs and provide an Azure API Key. Just like OpenAI directly, Azure OpenAI can be called in different ways, including through the Python SDK. You could also make direct HTTP requests (it's a REST-based API, after all). In addition, because you're now in the Microsoft world, .NET client-packages are provided for easy access from .NET languages. I find that to be an extremely compelling feature because AI is often built into existing applications to significantly enhance their usefulness, and many of those applications are written in languages other than Python.
The following is a C# example that uses the Azure OpenAI services to perform the equivalent tasks of the Python example above.
using Azure;
using Azure.AI.OpenAI;
var client = new OpenAIClient(new Uri("https://<APP>.openai.azure.com/";), new AzureKeyCredential("<YOUR API KEY>"));
var response = await client.GetCompletionsAsync("ChatBot", "Please tell me a story.");
Console.WriteLine(response.Value.Choices[0].Text);
As you can see, the code is very similar. In fact, I find the programming language used to call these kinds of AI services to be almost irrelevant. If the language can make HTTP calls, you're good to go.
There are a few aspects of the C# example worth pointing out: Note that the URL for the Azure OpenAI service is exposed as defined for my deployment specifically (unlike the direct OpenAI endpoints, which are the same for everyone and every use). As with everything in Azure, when you create an OpenAI resource, you specify the name as well as the deployment location. Azure gives you complete control over what region you'd like to deploy to (so if you have a legal or logistical reason to keep your AI service in a specific geographic region, you can do so through Azure OpenAI). Furthermore, you can create your own named deployments of LLMs. For instance, if you need a model that can generate marketing text, you could create a deployment called “Marketing Model” and then choose which actual model that maps to (such as “text-davinci-003”) and evolve that over time as more powerful models become available, without having to change your source code that accesses such a model. Nice! (In this example, I deployed a GTP3.5 model and called it “ChatBot.” See below for more details.)
A Simple Chat Example
Usually, the first implementation all our customers ask us to create is a chatbot, similar to chat.openai.com, but completely secure, so employees can use this kind of features set without giving away company secrets (as has accidently happened with Samsung. You might want to Google that). This is also a great example to go beyond the very basics of OpenAI LLMs, as it shows a chain of interaction.
To get started with a chatbot using Azure OpenAI, you first must create an Azure OpenAI resource through the Azure Portal (https://portal.azure.com), as shown in Figure 1. (Note: If you'd rather follow this example using OpenAI directly, you can follow all the concepts presented here, although the code will be different as the REST API will have to be used low-level). The user interface and flow for this is very similar to creating other resources in Azure (such as App Services). Currently, there aren't a lot of options or settings. The most important one is the name of the resource, which also defined the “endpoint” (the URL) of your OpenAI resource. Creating a new Azure OpenAI resource automatically creates API keys, which can be accessed through the Azure Portal (you'll need this a bit further down).
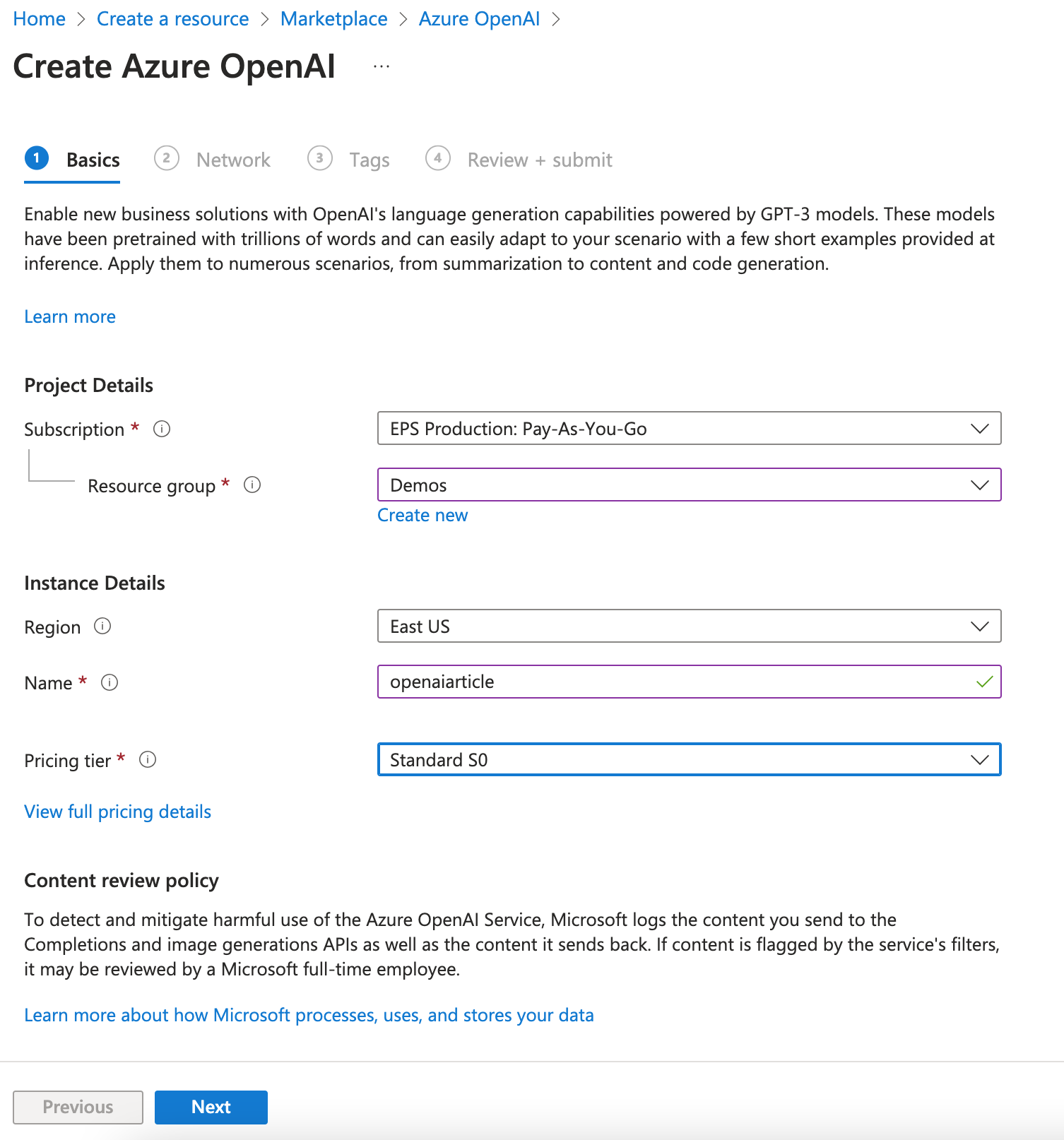
It's interesting that it's possible to select which region (and therefore, which data center and which geographic location) the service is to be deployed to (this is especially important if you have a legal requirement to run your AI in regions such as the European Union).
Note that as I'm writing this article, the list of available regions is somewhat limited. This is simply a resource limitation. In fact, there's a waitlist to even sign up for Azure OpenAI, although I hope that by the time you read this article, this limitation isn't an issue for you. Microsoft's working hard in establishing more data centers around the world that can run these kinds of workloads, which are often extremely resource intensive. However, the current list serves the purpose of making OpenAI services available in major regions. (For more information, visit https://www.codemag.com/StateOfDotNet and watch one of my recent recordings, such as the BUILD 2023 recap webinar, in which I provide more information on how fast Microsoft is bringing new data centers online and how incredibly large some of these things are).
Understanding Models
Once the fundamental Azure OpenAI resource is created, you need to “deploy a model.” To do this, you need to first understand what “models” in OpenAI are. When using applications like ChatGPT, an LLM is used to generate/calculate text responses to the user's input. At least, that's the simplified version of what really happens. To be at least somewhat more accurate, you must dig a little bit deeper.
When the user enters a “prompt” (the message sent to the LLM) in ChatGPT, there isn't just a single model that responds. And it doesn't respond with a complete message. Instead, multiple models make up a whole system that gets invoked to generate a response. Depending on the need and intent of the user, different models are more appropriate than others. Some models are great at creating elaborate responses but are slower and more expensive (because they are more resource-intensive to operate). Other models might be much faster but provide simpler responses (which may be completely appropriate for your specific need). And yet other models are better at specific tasks, such as creating or explaining source code. (Yes, LLMs can write programs - some better than others). Models also differ in their ability to handle large amounts of text. Each model supports a certain number of “tokens,” which roughly maps to text length (more on that below).
As you become a more experienced AI programmer, understanding the characteristics of various models, as well as staying on top of which new models become available, is an important skill. (A list of current models can be found at https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/models).
It's also interesting to understand that LLMs do not create large amounts of text. Instead, they predict a single word based on some prompt they receive. This may seem strange to you, as you've likely seen ChatGPT create large amounts of text. This is achieved by continuing to ask the model to keep running and generating “just one more word” until a satisfying complete output is achieved. This has no immediate impact on the samples in this article, but it's an interesting characteristic to understand. For one, it gives an idea of the performance characteristics (as you can imagine, returning a very large amount of text calls models many times and is thus a resource-intensive process). It also explains why models sometimes generate nonsense (although this is less of a problem with the most capable models, such as GPT3.5 or GPT4). The models simply don't “think” about the complete response they're going to give. Instead, generating “one more word” sometimes sends them down a path that isn't necessarily the most appropriate. Once the entire response is generated, it's possible to hand it back to a model and ask it whether it thinks the result is appropriate for the original prompt. Once it can analyze the entire result it generated, it often understands whether it was sensible or not. As it turns out, this is a trick that works rather well (especially with GPT4 models) to verify that a response is correct and prevent “hallucinations.” (I know a lot of humans that could benefit from the same thought process, but that's a different matter). If the model decides the response wasn't great, you can simply ask it to do it again, and the second time around, it'll likely do much better.
To create your chatbot, you can use a GPT3.5 model. To deploy this model, click on the link on the overview page of the OpenAI resource in the Azure Portal, which takes you to the Azure OpenAI Studio (https://oai.azure.com). This is a developer's tool like the developer's portal on openai.com (see above and also in the OpenAI articles in the July/August 2023 issue of CODE Magazine). Azure OpenAI Studio is a great tool to try out various techniques. It's also the tool used to create model deployments. To create yours, click on “Deployments” and then click “Create new deployment” (Figure 2). You can pick the model you assume is best (I generally start with GPT 3.5, which seems to be a good baseline). Unlike when using OpenAI directly, Azure OpenAI allows you to create your own name for the model. In this case, I named my model “ChatBot.” I could have also called my model deployment the same as the base model (“gpt-35-turbo,” in this case), but I prefer to give it a more abstract name. This way, if I later decide a different model is better suited for my chatbot example, I can change the model without having to change the model names in my code. A minor point perhaps, but one I like over the raw OpenAI approach of always going with the underlying model name.
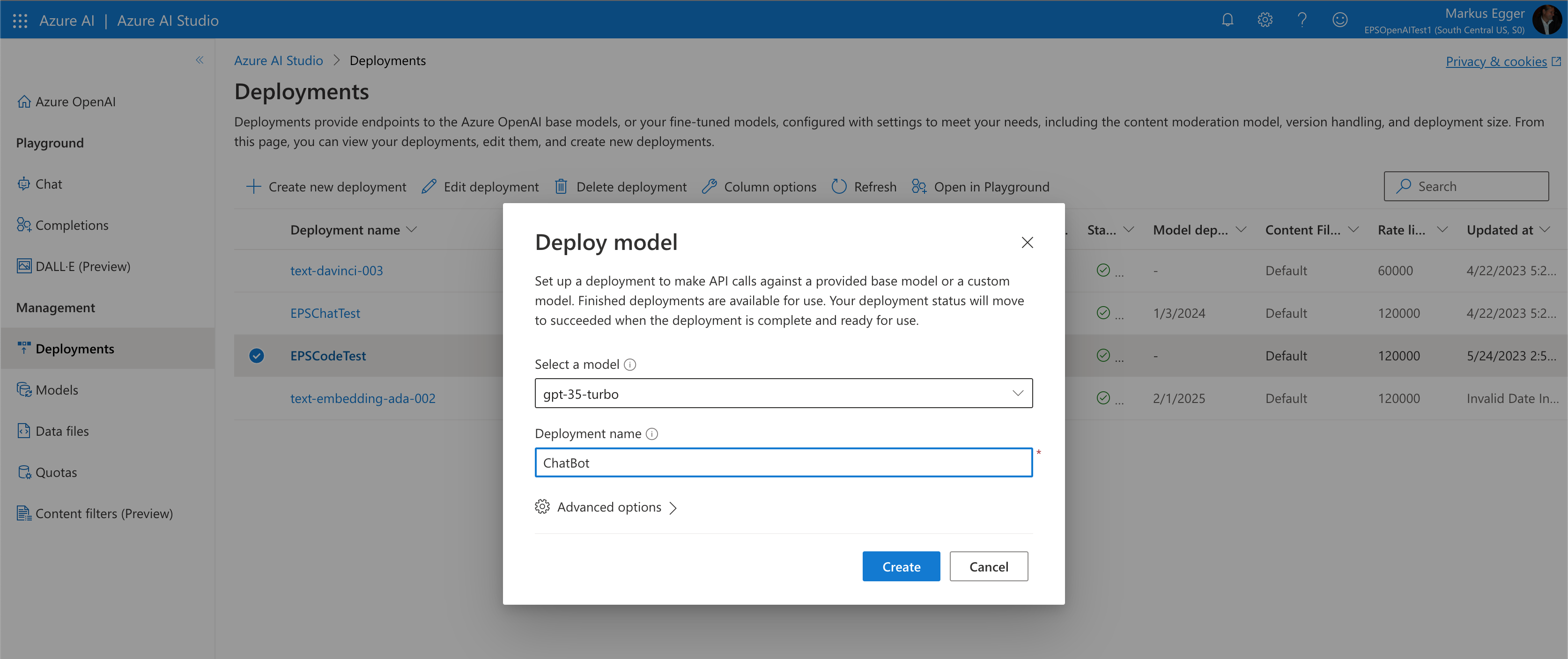
Now that you have the Azure OpenAI resource created and a model deployed, you can write code to start putting artificial intelligence to work. You can do so from any type of application you'd like. To keep things simple, I create a C# command line application. To access the Azure OpenAI services, I add the “Azure.AI.OpenAI” NuGet package to my project. Now, all I have to do is create an instance of the client-side object that's conveniently provided to me using this package, set the endpoint URL as well as API key (which can be found in the Azure Portal: see above), and I'm ready to start firing messages at the AI. The previous C# code snippet shows a first version of that.
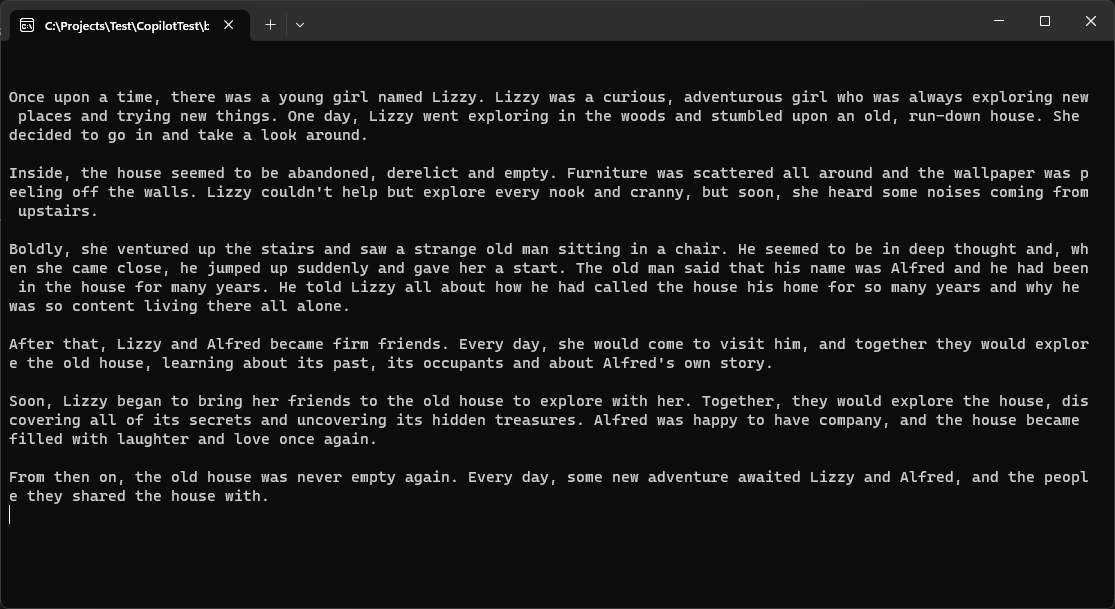
We haven't really done much here in terms of fine-tuning the setup, but this code already produces an amazing result (Figure 3). All this code does is call the service with a simple prompt (“tell me a story”) using all the default settings, yet the response you get is quite elaborate. Even this simple example produces results that would have been inconceivable just a few months ago. And we've just started to scratch the surface.
Understanding Prompts
A critical skill when coding AI (or even just interacting with AI from a user's viewpoint) is to understand how to best “ask it questions.” This is often referred to as “prompt engineering.” I find this term already becoming overused, as it describes a wide range of techniques, from users simply typing questions to developers coding very advanced flows of sequences of questions/prompts, often with large parts of this back-and-forth banter between a program and the AI completely hidden from the user. When I refer to “prompt engineering,” I usually refer to the latter. To me, prompt engineering implies an engineering component, the way a software developer understands it.
When sending prompts to an AI, there's a lot more than just a single block of text sent in hopes of a meaningful AI response. For one thing, there are different types of prompts. There's the “system prompt,” which is a prompt that's often sent to an LLM as the very first prompt. It's invisible to the user, and it's often used to configure the overall system. A system prompt might be something like this:
You are a professional customer service representative who works for
CODE Magazine and answers professionally and concisely. You only answer
questions that relate to CODE Magazine.
This type of prompt is never visible to the user. It represents additional input to the model that configures its overall behavior. This also reveals one of the major paradigm shifts that developers have to learn when developing against these AI models: Instead of setting parameters in a very precise way, you simply tell the model in plain English (or any other language, for that matter) what you want. It's both extremely powerful and somewhat scary, because the AI will interpret it any way it sees as most appropriate. The results will vary every time you interact with the AI. It's also extremely powerful and works quite well. Imagine what kinds of properties you'd have to set to achieve the same result that this system prompt will presumably achieve!
As you get more experienced in the use of LLMs, you will find this kind of programming exhilarating! I encourage you to experiment with system prompts. To spark your imagination, here's a prompt I often use when I demonstrate the Copilots we integrate into our applications:
You are a customer serice agent. You answer precisely yet light-heartedly and
sometimes you are funny. Because you are used for demo purposes, replace
all names that appear in the output with fake names for privacy reasons.
Now there's something you don't see every day! It solves a problem I originally struggled with when I wanted to show off AI in real-world applications. I often couldn't show the generated results for privacy reasons. But using a system prompt like this, the AI understands that everything that appears to be a name should be replaced with a made-up name instead. This is the kind of thing that's very difficult to do with traditional programming techniques - how would you even write an algorithm that detects what's a name, let alone replace it with fake names, and then apply that fake name consistently going forward in follow-up conversations? Because we're dealing with a model that is, at the very least, very good at applying statistical mathematical tricks to fake intelligence, it understands this kind of request and does quite well with it. Amazing indeed!
Here's one more system prompt I often use to amuse myself when I sit in front of my computer at 3 a.m. to meet the latest deadline (after all, you gotta have some fun every now and then, don't you?):
You respond in the style of John Cleese from
Monty Python, acting as a medieval peasant.
If the output created by this doesn't put a smile on your face, brave sir knight, I must humbly request you turn in your geek card. <g>
As you can imagine, using a system prompt effectively is important. You want to use a system prompt that's precise. At the same time, you don't want the system prompt to be too long. After all, when dealing with LLMs, you're constantly battling size limitations, as they can only process a certain amount of text. Therefore, try to be specific without wasting too much space on the system prompt.
If this doesn't put a smile on your face, brave sir knight, I must humbly request you turn in your geek card!
The next type of prompt we're interested in is the user prompt. This is the core question you send to the AI. If you've ever used ChatGPT, the user prompt is what you type into the interface on the web page. A common usage pattern is to let the user enter the text and then send it to the AI as the user prompt. Note that this isn't the only way to use this type of prompt. Very often, you'll engineer other ways of coming up with the input text (as you will see below). For now, let's enhance the prior example by reading the input from the console so the user can enter anything they want.
Also, while I'm at it, I'm going to switch from a simple “completions” scenario to the slightly more advanced “chat completions” scenario. A chat is essentially a series of completions and the API is very similar, but it makes it easier to create larger conversations.
The new example, which combines a system prompt and a flexible user prompt, now looks like this:
using Azure;
using Azure.AI.OpenAI;
var client = new OpenAIClient(new Uri("https://<APP>.openai.azure.com/";), new AzureKeyCredential("<YOUR API KEY>"));
var options = new ChatCompletionsOptions { MaxTokens = 1000 };
options.Messages.Add(new ChatMessage(ChatRole.System,
"""
You are a friendly and funny chap, used to amuse an online audience.
You respond as if you were John Cleese from Monty Python but with
an old-English, medieval way of talking.
"""));
var userPrompt = Console.ReadLine();
options.Messages.Add(new ChatMessage(ChatRole.User, userPrompt));
var response = await client.GetChatCompletionsAsync("ChatBot", options);
Console.WriteLine(response.Value.Choices[0].Message.Content);
This generates a response, which is also known as a “prompt.” The AI considers itself to be an “assistant” to the person using it (or at least OpenAI considers it as such - the AI itself has no opinion on the matter) and therefore, this is known as the assistant prompt.
You might wonder why the response is considered a “prompt” at all. Isn't it just the “response?” Yes and no. As you have longer conversations with the AI, you somehow need to preserve the state of the conversation. For instance, if you ask the AI “What is a Ferrari,” it responds with something like “an Italian sports car.” If you then subsequently ask “what is its typical color,” the AI needs to somehow know what “it” is. To us humans, it's obvious that “it” refers to the “Ferrari” from the prior question. However, an LLM is a completely stateless system. It does not memorize prior answers or dialogs. Therefore, if you want the AI to understand such context, you must send it all the parts of the conversation that are meaningful for the context. The easiest way to do so is to simply add to the collection of prompts, including the assistant prompts, on every subsequent call:
using Azure;
using Azure.AI.OpenAI;
var client = new OpenAIClient(new Uri("https://<APP>.openai.azure.com/";), new AzureKeyCredential("<YOUR API KEY>"));
var options = new ChatCompletionsOptions { MaxTokens = 1000 };
options.Messages.Add(new ChatMessage(ChatRole.System,
"""
You are a friendly and funny chap, used to amuse an online audience.
You respond as if you were John Cleese from Monty Python but with
an old-English, medieval way of talking.
"""));
while (true)
{
Console.ForegroundColor = ConsoleColor.White;
Console.Write(">> ");
var prompt = Console.ReadLine();
if (prompt?.ToLower() == "exit") break;
options.Messages.Add(new ChatMessage(ChatRole.User, prompt));
Console.ForegroundColor = ConsoleColor.Cyan;
Console.WriteLine();
var currentResponse = string.Empty;
var response = await client.GetChatCompletionsAsync("ChatBot", options);
Console.WriteLine(response.Value.Choices[0].Message.Content);
Console.WriteLine();
// Adding the AI response to the collection of
// prompts to preserve "state"
options.Messages.Add(new ChatMessage(ChatRole.Assistant, currentResponse));
}
In this version, you first set up a system prompt. Then, you enter a loop (until the user types EXIT) and collect a new user prompt, add it to the collection of prompts, send it to the AI, retrieve the assistant prompt back (the answer), and display it in the console (Figure 4). You then add the assistant prompt to the collection of prompts, add the next user prompt, and repeat the process. This way, all of the relevant context is available to the AI on every call, and thus it can generate meaningful responses as if it remembered the entire conversation.
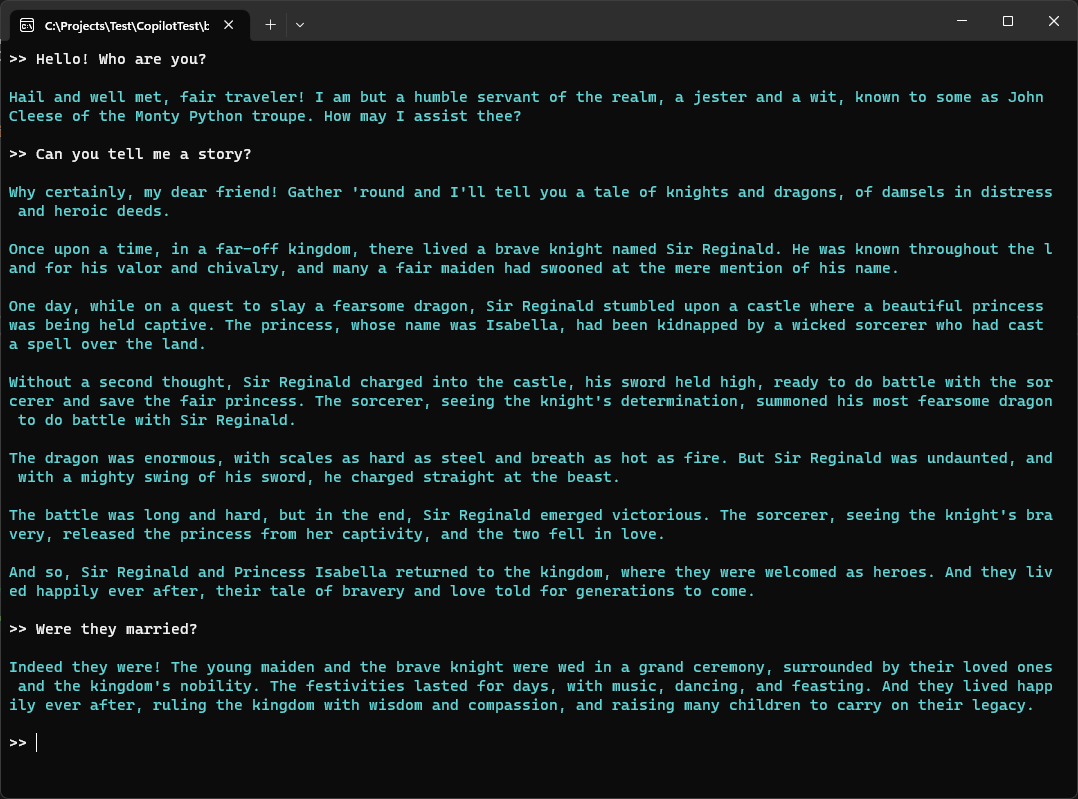
You may notice that the approach of adding to the queue of prompts could create a very large amount of text quite quickly. As I've already pointed out above, language models have size limitations. You'll find yourself constantly wrestling with this limitation. Even the best language models are quite limited in that respect. So, what can you do if the collected size of the prompts gets too long? The simplest answer is that you start dropping user and agent prompts once they get above a certain number. (For instance, Bing's chat feature currently starts dropping prompts after five roundtrips). Another option is to get a summary of the most important aspects of the conversation so far and stick that summary into a single prompt.
Note: There are various prompt engineering techniques that can help with this problem. For instance, instead of sending everything back and forth, you could ask the AI to summarize and rephrase the current question in a way that includes all required information. I will dive deeper into such techniques in a future article.
You may find yourself wondering how you'd extract a summary of the most significant points of a conversation. It's an extremely difficult programming task, after all. But the answer is right in front of your eyes: Ask the AI to summarize all the prompts for you. You can simply start a new chain of interaction with the AI independently of your main conversation. You can create a new system prompt that indicates to the AI that it's used to create concise summaries. You then send it the entire collection of previous prompts and add a new user prompt that asks the AI to summarize everything. This is an example where the user prompt isn't, in fact, generated by a human user, but instead, the “user” is your application. This generates a new assistant prompt with a summary of everything that has happened so far. On your main conversation, you then clear out your collection of prompts (except the system prompt) and add the new/single assistant prompt containing the summary. You proceed from that point forward with the next human-generated user prompt. This works quite well! The AI won't be aware of every single detail of the prior conversation (and neither are humans when you talk to them for a while), but it will have enough context to where it's usually not apparent that this truncation happened. In my experience, this creates quite a natural flow that will do an amazing job of making you think you're conversing with an actual person.
Understanding Tokens
One of the questions as yet unanswered is “when is a prompt sequence too long?” Each language model has a certain text size limitation. This includes all the text going in and out of the model. In other words, limitations are a combination of input and output. Let's say the size limitation is 1000 characters and you send it a prompt that's 200 characters long: The response can't be longer than 800 characters.
However, limitations aren't measured in characters or words. Instead, they are measured in “tokens.” A token is a mathematical representation of a word or a text sequence such as special characters, line feeds, white space, and so on. There's no simple answer to how characters and words are converted into tokens. There are some useful estimates, such as “a token, on average, encodes about four characters” or “think of tokens as syllables.” Such estimates give you a rough idea and some context, but they can also be wildly wrong.
The correct answer is to convert text into tokens to get the actual and accurate result. This can be done using a “tokenizer.” In Python, you can use a library called TikToken. In C#, the equivalent is - wait for it - SharpToken. You can add SharpToken as a NuGet package and then use it to encode text like this:
var encoding = SharpToken.GptEncoding.GetEncodingForModel("gpt-4");
var tokens = encoding.Encode(text);
var tokenCount = tokens.Count;
Note that you need to choose the right token encoding for the model you're using. However, for any of the modern GPT models, “gpt-4” encoding works well (there's no separate encoding for GPT 3.5).
This gives you a list of integer numbers (“token” is a fancy term for “integer number,” in this case). You could turn this list of numbers back into the original text (and all LLMs operate on such tokens rather than the actual text - after all, all artificial intelligences are fancy math processors, and that requires numbers). You could turn tokens back into the original text like so:
var encoding = SharpToken.GptEncoding.GetEncodingForModel("gpt-4");
var text = encoding.Decode(tokens);
For our purposes, however, you'll just use this to figure out the exact length of the prompts. If you calculate the tokens for every prompt in the sequence, you know when you go above the published maximum token size for the model you've chosen (see Microsoft's model reference already mentioned above). When you detect a problem, you can start truncating or summarizing the prior history as described above. Voila!
In case you are interested what tokens are like, the text “Hello, world!” results in the following integer tokens:
9906, 11, 1917, 0
One part of all of this that's still a bit fuzzy is that the maximum token count includes the output as well. Let's say that you use the gpt-35-turbo model, which has a documented maximum token count of 4,096. Applying a very rough estimate, this is about 8,000 words. (The largest token count currently supported by any OpenAI model is 32,768 in the gpt-4-32k model. Not surprisingly, it's also by far the most expensive model to use). If you use the tokenization approach to determine that you've already used up 3,700 tokens (to make up an example), that leaves 396 tokens maximum response size (about 800 words). To not create an error response, you then have to limit the response size to a maximum of 396 tokens. This can be done by setting the corresponding property on the API. Not everything in OpenAI is specified in plain English. There are a handful of properties, such as size limits or randomization settings that have an impact on the predictability of the generated response. See below for an example.
Streaming Results
In the examples shown so far, you've fired a request into OpenAI and waited for the complete response to be provided. This is known as “synchronous access.” However, when using the ChatGPT application, users observe a different behavior, where word after word appears in the user interface, almost as if the AI actually spoke one word after another. This is a pattern that is quite natural and one that users seem to have already come to expect, even though this entire paradigm hasn't been around very long. This behavior is known as “streaming.”
Using the C# API, it's relatively simple to create this sort of streaming behavior. Listing 1 shows the complete implementation.
Listing 1: A complete chat implementation with streaming response.
using Azure;
using Azure.AI.OpenAI;
var client = new OpenAIClient(new Uri("https://<APPNAME>.openai.azure.com/";), new AzureKeyCredential("<YOUR API KEY>"));
var options = new ChatCompletionsOptions { MaxTokens = 1000 };
options.Messages.Add(new ChatMessage(ChatRole.System,
"""
You are a friendly and funny chap, used to amuse an online audience.
You respond as if you were John Cleese from Monty Python but with
an old-English, medieval way of talking.
"""));
while (true)
{
Console.ForegroundColor = ConsoleColor.White;
Console.Write(">> ");
var prompt = Console.ReadLine();
if (prompt?.ToLower() == "exit") break;
options.Messages.Add(new ChatMessage(ChatRole.User, prompt));
Console.ForegroundColor = ConsoleColor.Cyan;
Console.WriteLine();
var response = await client.GetChatCompletionsStreamingAsync("ChatBot", options);
var sb = new StringBuilder();
await foreach (var choice in response.Value.GetChoicesStreaming())
{
await foreach (var message in choice.GetMessageStreaming())
{
if (!string.IsNullOrEmpty(message.Content))
{
Console.Write(message.Content);
sb.Append(message.Content);
}
}
}
Console.WriteLine();
Console.WriteLine();
options.Messages.Add(new ChatMessage(ChatRole.Assistant, sb.ToString()));
}
This creates output that's more pleasing and natural, as it eliminates potentially large wait states (it can take several seconds to produce responses, and often more for very large responses). It's an easy way to give the user the impression that the response was instantaneous.
With that said, I haven't quite made up my mind about whether this is an approach I want to use going forward. I've already mentioned above that LLMs can produce incorrect output or outright “hallucinate.” (I'm not a big fan of this term because I feel it gives too much agency to AIs. After all, we're not dealing with people or intelligent beings. We're dealing with statistical math engines that produce statistically probable text output. They do not “hallucinate.” It simply turns out that sometimes nonsense is statistically the most likely answer.) I wonder if we'll get ourselves into trouble by letting LLMs dump “stream of consciousness” types of answers on users without first checking the result. Checking the result is quite possible (as discussed above), but to do so, you first need to have the entire result, then check it, redo it if you're not happy with the result, and then show it to the user. This is contrary to streaming output. However, if the response takes a while, you'll have to employ other user interface tricks to keep the user happy and fool them into thinking the response was quicker than it really was. After all, you don't want a user interface that appears to be doing nothing for more than a second.
At this point, I'm assuming that we'll use both streaming and non-streaming interfaces. When it really must be right (as is often the case in enterprise scenarios), we probably won't be able to stream. On the other hand, there are plenty of scenarios where accuracy isn't as important (such as when using AI to help us write an email or a marketing text), in which streaming is an easy way to create a good user experience.
Adding Your Own Data
We have now created a rather nice chatbot that can converse coherently and probably fool people into thinking they are talking to a person. This is impressive! But it can only hold interest for a short period of time. To make a truly useful artificial intelligence, or even a Copilot, you need to make the AI understand your specific needs, data, and institutional knowledge.
Let's create an example scenario, in which you imagine that you're running a vacation rental business that rents out properties to vacationers all over the world. Vacationers may have many questions about the properties they rent, as well as the area they are visiting. I'm sure everyone in the vacation rental business must have answered questions such as “How do I turn on the air conditioning system?” or “How do I operate the safe?” a million times and would rather offload such tasks to an AI that's available 24 hours a day and doesn't get annoyed easily.
In his article in the July/August 2023 issue of CODE Magazine, Wei-Meng Lee created an example using the Python LangChain package to index his entire collection of CODE Magazine issues, so the AI could answer specific questions related to everything CODE has ever published. This is very useful, but for the vacation rental example, you need to go a step further. Wei-Meng created a static index of all magazines and then kept using it (an approach that is useful for some scenarios), but you need to use data that is current up to the minute. Furthermore, and more importantly, you need to apply additional logic to create a correct and meaningful answer. For instance, it's not useful in this scenario to index the documentation you have for all air conditioning systems in all of the vacation homes. Instead, you need to know which property the vacationer has rented, whether it has an air conditioning system (or whether the vacationer is authorized to use it), and then only use this information for the AI to create an accurate answer. (Another concern that applies in very many scenarios is security and access rights.)
A great way to support such a scenario is a pattern known as Retrieval Augmented Generation (which results in the somewhat unfortunate acronym RAG). The general idea is that you first let the user enter a question, such as “How do I turn on the AC?” Then, you must retrieve all of the information you have about the air conditioning system specific to the property the user has rented. You then take all that information, hand it to the AI, and let the AI answer the original question.
To make a truly useful AI, you need to make it understand your own data and institutional knowledge.
In some ways, this is easier said than done. First, you need to detect the user's intent. Do they want to just chat about something LLMs know (such as "what is an air conditioning system?"), or do you need to retrieve different types of information? In this example, intent detection is relatively trivial, assuming you're creating an AI specifically for answering such questions. The intent is always that you need to find documents related to the property they rented. (Similarly, Bing Chat always knows that the intent includes some sort of web search before the question can be answered.) Therefore, intent detection isn't a big issue for this scenario. However, I'm mentioning intent detection here, because many Copilot scenarios must do some heavy lifting around this concept, and I'll explore this in a future article. (For instance, a user's question in a business application may have to do with customers or with product databases or with invoices or… you get the idea. To have an AI answer such questions, you first need to figure out what domain the user's input relates to. AI can help answer that, but it isn't trivial). It's generally safe to assume that for any AI Copilot scenario, intent detection is the first priority for any request.
Because you know that the user's intent includes searching for information you may have, the next step is to figure out which documents apply. But how can you do that? If you had a bunch of text description or even documents in a SQL Server database, you could retrieve them from there, but how would you turn the question “how do I turn on the AC?” into a SQL Server query that returns appropriate documents? After all, SELECT * FROM Documents WHERE Body = 'how do I turn on the AC?' isn't going to return anything useful.
When it comes to this new world of AI development, I've discovered that things are a lot easier if your system has access to other AI-powered services. For instance, if you use Azure Cognitive Search, it would be somewhat easier to return a list of documents that match the criteria. Not just that, but it could return such documents in a ranked fashion, with the most important ones being returned first. You could send it a search term such as “air conditioning manual” and filter it by the name of the property the vacationer has rented. This leaves us with the problem of turning the original question (which might be much longer and include other aspects, such as "how do I turn on the AC and how much will it cost me to do so?") into a useful search term (such as “air conditioning manual pricing”) that will return useful information. (Note that the user may use the term “AC” and you may have to search for “air conditioning”).
Again, the answer becomes clear once you've adopted the new style of development in this new world driven by AI: You ask a large language model to come up with a useful search term. A user prompt such as this will give you a starting point:
Your task is to create a search term useful for Azure Cognitive Search.
Provide a search term for the following prompt:
How do I turn on the AC and how much will it cost me to do so?
As you can see, this prompt is “engineered” to include a request related to what the user has entered as well as the user's original question. This prompt can be created by simply creating the string in memory. I find it easier to create at least a simple text template engine that helps with this task. I've created one internally that supports the following syntax. (Note: CODE may make it available as an open-source engine if there's enough interest. Feel free to contact me if you feel it would be useful for the community.) Using such an engine, you might be able to create a template like this to create the output string:
Your task is to create a search term useful for Azure Cognitive Search.
Provide a search term for the following prompt:
{OriginalQuestion}
Note that there are some components out there that already do something similar, such as LangChain in Python. Microsoft's announced (but unavailable as I write this article) Prompt Flow engine presumably also supports similar syntax.
If you fire this prompt (completely invisible to the user) into OpenAI, it creates a useful result that can then be used to retrieve documents from Azure Cognitive Search (or similar services, such as Amazon's Elastic Search). However, responses are often somewhat unpredictable. Sometimes, you get a response such as the desired “air conditioning manual price.” Sometimes, the response is wordier as in "a good search term might be ‘air conditioning manual price’", which is correct, but not that useful. Sometimes it provides the first answer, but wraps it into double quotes, which has special meaning to search engines and thus creates wrong results.
How can you handle this problem and what creates it in the first place? For one thing, you can turn the “Temperature” down to 0. “Temperature” is a parameter you can send to an LLM. It's a value between 0 and 2 (usually defaulted to 0.7) that defines the randomness of the response. If you turn this parameter to 0, the response to the same question will be predictable and consistent. The higher the value, the more random the response becomes. High randomness is useful if you want to write stories, but in technical scenarios like this, you want high predictability, so I recommend turning randomness to 0 for this operation.
Another problem lies in the core nature of this request. It's what is referred to as a “zero-shot prompt.” This means that you simply sent a request to the AI but provided “zero guidance” (or “zero examples”) as to what you wanted in return. Therefore, it tries its best in coming up with a response, but it will be somewhat different in nature for each request based on the question the user asked. Try to unit test that!
In my experience, far better results are achieved with prompt engineering techniques known as “one shot,” or, better yet, “few shot.” In a “few shot prompt,” you provide a few examples in addition to the question. Therefore, I propose that you use the following prompt template:
Your task is to create a search term useful for Azure Cognitive Search.
Provide a search term for the following prompt:
Q: How do I open the safe?
A: safe manual
Q: How do I unlock the door with the keypad?
A: keypad door operation
Q: What attractions are there around the property and what do tickets cost?
A: local attractions
Q: {OriginalQuestion}
A:
In this example, I provided patterns of what I expect. Those patterns may not be very close to what the questions are that the user asks, but they still provide enough guidance to the AI to drastically improve the response. Also, because it establishes a pattern of questions (Q) and answers (A), the returned response will be similar to what's in the provided answer examples (which, for instance, do not have quotes around them). It doesn't matter how you format your few-shot prompt. For instance, instead of having used “Q:” and “A:” to indicate questions and answers, I could have used “User:” and "Search Term:". It just matters that I provide a few examples of what I expect. (The shorter version is preferrable, because the API charges by token count).
This may seem strange at first. But hey! Welcome to the new world of AI! <g> These types of prompt engineering techniques are among the critical skills to learn when it comes to AI programming. I'm sure CODE will produce quite a few articles and blog posts about these sorts of techniques for years to come.
There's one more interesting aspect when it comes to finding a good search term and that relates to the model you use. When starting with LLM development, the instinctive reaction is to always use the most powerful model. But the more powerful the model, the slower it is and the more each call costs. API calls are usually charged for in 1,000 token increments. They're cheap individually, but they can add up quickly! Therefore, choosing the right model is often critical for performance and economics.
Because you don't need the AI to write a novel that can win the Pulitzer Prize in response to a request to find a good search term, you can probably do with a less capable model that's cheaper and faster. As more and more models become available, perhaps there may even be models in the future that aren't as crazy resource-intensive and can run on local computers without incurring any API expenses. Whatever the case may be, a good prompt engineer and AI developer will consider these tradeoffs on each call to the AI. A single question a user asks may invoke several different models behind the scenes to ultimately come up with a good answer. For this specific need, I encourage you to experiment with some of the simpler models to find a search term before you then use something like GPT3.5 or GPT4 to follow the next steps I'm about to describe.
Augmenting Prompts
Now that you have a search term, you can fire that search term into Azure Cognitive Search and retrieve a list of ranked documents.
Note: This assumes that you already have a list of documents in Cognitive Search (or a similar index). Creating such an index is beyond the scope of this article, but the short version is that you can create a Cognitive Search resource in Azure (similar to OpenAI resources or App Services and many others) and then add documents and other content either manually, or by having it automatically sync with various data sources. This allows you to add anything from PDFs and HTML documents all the way to database content. Some of this is fully automated, although I often find that it's useful to hand-craft indexes to achieve the best results for AIs. I'll explore this in detail in a future article. For now, let's assume that there's such a search index and you've retrieved a list of information from it based on the search-term you had the AI generate above.
At this point, you need to generate a final user prompt that you can hand over to the AI to generate a meaningful answer. You do this by injecting or “augmenting” the prompt with the information you retrieved before a response is generated (thus the name “Retrieval Augmented Generation”). In its simplest form, you create a prompt string that literally includes the content of the documents you retrieved. Showing the complete prompt might take up several pages in this magazine, so let's look at a conceptual prompt template instead:
Based on the following documents, please answer the question below:
<% foreach document in documents %>
====
{document.Title}
{document.Content}
<% end foreach %>
Answer this question: {OriginalQuestion}
I think you can see where this is going: You create a large prompt with all the content you retrieved from the search. At the very beginning, you state what you want the AI to do. The result is each document with title and actual content. (Note that I added an arbitrary separator sequence of four equal signs before each document. This is another prompt engineering technique I learned from experience that seems to help the AI make sense of what I give it). Finally, I ask the AI a second time (yet another technique that usually improves the result) to answer the original question the user had, and then the question (such as "how do I turn on the AC?") is merged into the prompt.
The result is output that is “grounded” in the specific information you provided. It will be of very high quality and far less prone to hallucinations than what you'll encounter in raw ChatGPT. Also, the information you provided will remain private and secure. It won't be passed on to OpenAI for further model training or anything of that kind. (Figure 5 shows CODE's internal knowledgebase, which now features our own built-in CODE Copilot. It was built on this very technique).
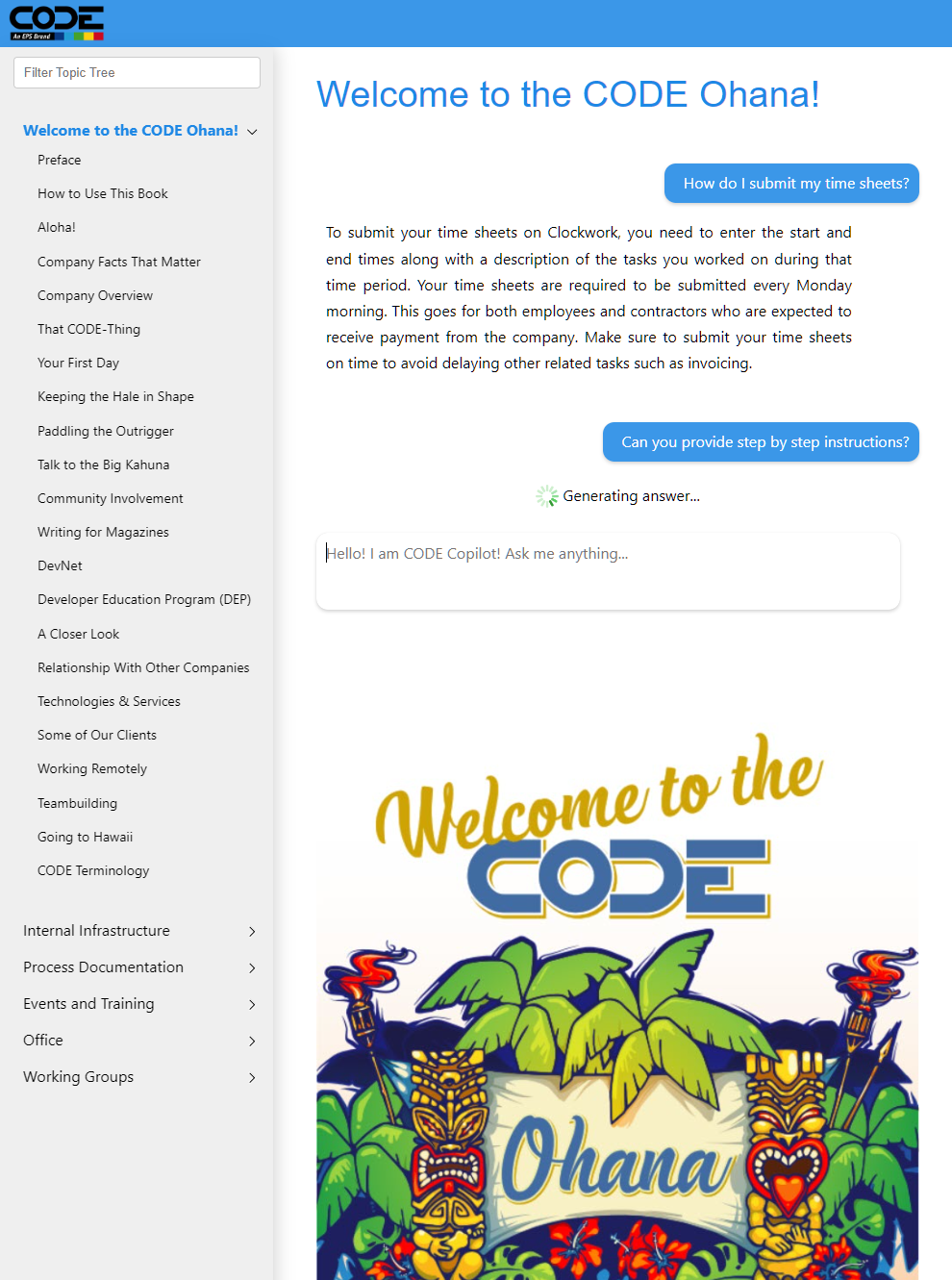
One aspect I haven't talked about yet is that of size. Again, you're up against token limits, and information returned from search services can be lengthy. However, it's also ranked, meaning that the most applicable results are returned first. I have used a simple token count mechanism where I add up documents as long as I'm under the token limit and then ignore the rest. After all, it's less important. This works in many scenarios. Another option is to make multiple calls to the AI to summarize each document, so it's much shorter yet maintains the important parts. This way, you can inject far more information, but it is also more resource intensive.
In future articles, I'll explore the details of making search index use more efficient. One way to do so is to tune what gets indexed. For instance, the indexed document can be summarized when it's saved into the index, and therefore, a summarized and smaller version can be always available if needed. Another technique I'll explore in future articles is to handcraft indexing mechanisms for rectangular data (business data stored in databases such as SQL Server, or invoices, products, and so on) so it can be found by AI.
Using Pre-Baked RAG Features
The pattern I just introduced is useful for quite a few scenarios, which is why I went through it in a manual fashion here. I predict that you'll spend quite a bit of time implementing the RAG pattern for a wide variety of uses. With that said, it isn't always necessary to do this by hand. The example I've shown above could have also been automated away completely. Microsoft has introduced features in Azure that allow combining OpenAI LLMs with Cognitive Search directly. Using this approach (which is currently available in a preview version), you can automatically link Azure Cognitive Search to OpenAI, making much of this happen transparently and without knowing how the RAG pattern works. It can be used to add anything in Cognitive Search as well as data stored in Azure Storage and, to a limited extent, even in SQL Server.
How well this will work remains to be seen once Microsoft makes more of these features available to us. I predict that it will be useful in a lot of scenarios. I also predict there will be a lot of scenarios where you will still do this manually, either because you want to incorporate different data sources, or because you want to add more logic (such as "which vacation rental property has the user rented?") to your systems.
This is a good example of where Azure OpenAI shines over just OpenAI. After all, it's not OpenAI's job to incorporate RAG patterns into their models. But it is Microsoft's job to add more and more integration features of this kind, and I expect this to happen at a rapid pace. This is one of the main reasons I often choose Azure OpenAI over OpenAI directly (even though I use both approaches).
Conclusion
There you have it! You now know some of the fundamental techniques required to build Copilot-powered applications. Admittedly, there remain many unanswered questions, such as “how do you create a search index on SQL Server data?” or “how do I go beyond a command-line user interface?” Similarly, there are specific tasks to which solutions may not be immediately apparent, such as summarizing large blocks of information or detecting user intent in scenarios that require consolidation of many different types of data, information, and features.
These topics are beyond the scope of this article, but not beyond the scope of what we intend to cover in CODE Magazine in upcoming issues. In fact, I anticipate that we will continuously publish a wide range of articles that all revolve around this new world of software we now all live in. I hope you'll stay tuned for my own articles, blog posts, webinars, and presentations on the subject, and you'll find that many other authors and presenters are creating similar content.
I'm very excited! In the thirty years I've spent in the software industry, I've never experienced anything quite like this. The pace of development is incredible and even somewhat intimidating. At the same time, the surprising results AI-driven software can produce are fascinating. It doesn't happen often that software you wrote completely surprises you in the capabilities it exhibits, but that's exactly what happens on a regular basis with software that uses LLMs as a backbone. It is easily the most fun I've ever had in development.
I anticipate a fascinating journey. I hope you'll join me!
