


We're living through interesting times. It's estimated that the human brain holds 2.5 petabytes of memory. Google Bard was trained in a dataset of around 1.56 petabytes. Yeah, we humans are still ahead, but consider that Bard took four months to learn all that, and Bard is far better than a human in making interconnections in so many ways. I use Bard as an example, but ChatGPT's numbers are similar.
Did you know that, since 2011, computer vision has been better than human vision in recognizing objects? Pair that with the ability of modern cameras and ultrasonic sensors to see in thick fog, across occlusions, in pouring down rain, and in ultraviolet and infrared spectrums. Can these technologies not one day help us to drive? After all, how do airplanes land in thick fog today?
It's not a surprise that almost every tech CEO can't seem to complete a sentence without the word “AI”. In fact, at the latest Google keynote, the word AI was mentioned over a hundred times. I'm throwing all these numbers at you, but I just asked ChatGPT to tell me all this and I'm just repeating what it found.
I blogged about the societal impact and how we aren't ready for the sea change AI is about to bring into our lives (https://winsmarts.com/thoughts-on-chatgpt-and-ai-a13d8a503638), but I must admit, I approach it all with both caution and excitement.
In this article, I'll assume that you have no background in AI and explain where tech is from an OpenAI and Microsoft ecosystem perspective, and maybe even talk a bit about what the competitors are up to.
A Brief History of OpenAI
Although it's tempting to dive into code, it's more important to understand the ecosystem and the path of how we got here. This is especially true for ground-breaking technologies, such as the printing press or AI. OpenAI isn't a technology. It's a research laboratory consisting of a nonprofit called OpenAI Incorporated and a for-profit subsidiary called OpenAI Limited Partnership.
It was started in 2015 by a number of powerful people and companies so the organization could freely collaborate and make its patents and research open to the public. The researchers worked with the best intent, gave up huge salaries at Silicon Valley tech firms, and focused on the mission. Over the years, they released and invented some amazing things.
As it happens with any such venture, once it becomes important, not only does it need more money, it also attracts opportunities to make money. So in 2019, OpenAI transitioned to “capped for profit,” with the profit capped at 100 times any investment. This helped OpenAI attract investment and money attracts talent. Around the same time, Microsoft invested a billion dollars in OpenAI.
As time progressed, in 2020, OpenAI announced GPT-3, which stands for generative pre-trained transformer 3. Don't worry if it doesn't make a lot of sense yet, I'll explain all this momentarily. GPT-3 was something that, when given a prompt, generated human-like text. You could converse with the computer in a number of natural languages.
In 2021, OpenAI introduced DALL-E, which was a deep learning model that could generate images from descriptions. You could describe anything, like a teddy bear riding a horse on a beach on Mars, and it generated an image for it.
In 2022, OpenAI released a free preview of ChatGPT 3.5, which received over a million sign ups in the first five days. People were absolutely amazed at the capabilities of this new chat-based interface.
In January 2023, Microsoft announced a $10 billion investment in OpenAI, and then continued to integrate ChatGPT into the Bing search engine. Subsequently, it appeared in Edge, Microsoft 365, and other products, under the overall brand name of “Copilot.” If you've tried GitHub Copilot, that's an example of a large language model that's been fine-tuned for code.
In March 2023, OpenAI released GPT-4.
The competition hasn't been sitting idle either. Google was clearly alarmed at this flurry of activity, and an internal document from Google (leaked to the public) was called “We have no moat and neither does OpenAI,” https://www.semianalysis.com/p/google-we-have-no-moat-and-neither. Let's be honest, for the past 15 years, Google has been the gateway of information for all of us. This is an incredible power they've wielded; they can show us ads and charge money for them. Or they can suppress information they deem not worthy of our eyeballs. But with the advancements in the cloud and computing power, the availability of data, and many very intelligent minds at work, the moat has become about as relevant as castle walls once airplanes were invented.
Times have changed, and Google has risen to the challenge with their equivalent of ChatGPT called “Bard,” and similar such products.
A Crash Course in AI
When you read anything about AI, you're greeted by a number of terms. Generative AI? Machine learning? Deep learning? Reinforcement learning? What does all this mean? Let us understand some basics before moving forward.
First, Artificial intelligence (AI) is a branch of computer science that deals with the creation of intelligent agents, which are systems that can reason, learn, and act autonomously.
Machine Learning or ML is a subfield of AI. It gives computers the ability to learn without being explicitly programmed to do something. The thought is that if you show the computer enough data, you have an algorithm, and based on that, the computer makes a prediction for data it's never seen before. The computer crunches a lot of data ahead of time, and creates a model. Based on that model, it makes predictions.
For example, I'm creating a model to identify a dog. If you've seen enough dogs, you know a dog is furry, has four legs, a tail, ears, usually acts like a stomach on legs. If I show you a Labrador, you know instinctively that it's a dog. If I show you a dachshund, you puzzle about how weird and long this dog is but you still know it's a dog. If I show you a Doberman and his tail is docked, you might pause, thinking that all dogs had tails. But you've seen enough dogs, and other animals, to know that this too, is a dog. Your model has seen a lot of data and it's a good model.
There are some common ML algorithms. Linear regression, for instance, is a simple algorithm that predicts a continuous value. A logistic regression can be used to predict a binary value and so forth.
ML can be split into two types: unsupervised ML models and supervised ML models. The main difference between the two is that the input data for supervised ML models is labelled. Let's take the example of dogs again. If I fed your model thousands of pictures, and clearly labelled what is a dog and what is not, the computer could use that input data to improve its understanding by validating it against the labels provided. In other words, in supervised learning, the computer learns from past learnings to predict future values. It takes a subset of the data and runs your algorithm against it to create a model. Then it uses the rest of the data to run against your model, and compares the predicted labels with the supplied labels. This gives you an error where your predictions didn't match the labels. Then you use that as input to tweak your model further until you minimize errors. This general flow can be seen in Figure 1.
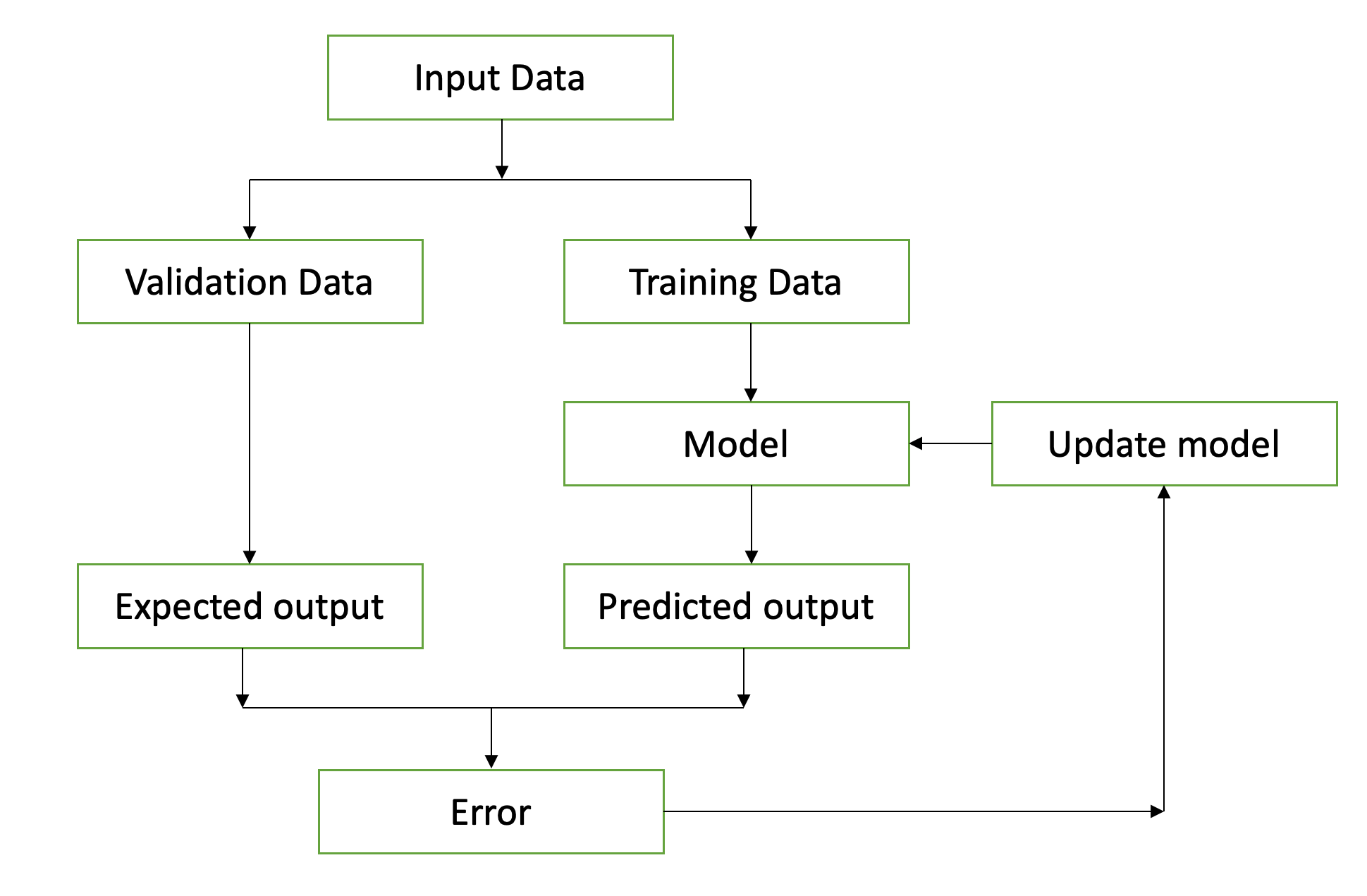
A real-world example for supervised learning could perhaps be a bunch of biological markers from a person's test results to predict whether or not a person has diabetes.
Unsupervised learning, on the other hand, is where the input data isn't labelled, and the computer is tasked with recognizing patterns or making sense of such unstructured data, as depicted in Figure 2. A good example of this could be clustering or detecting anomalies.
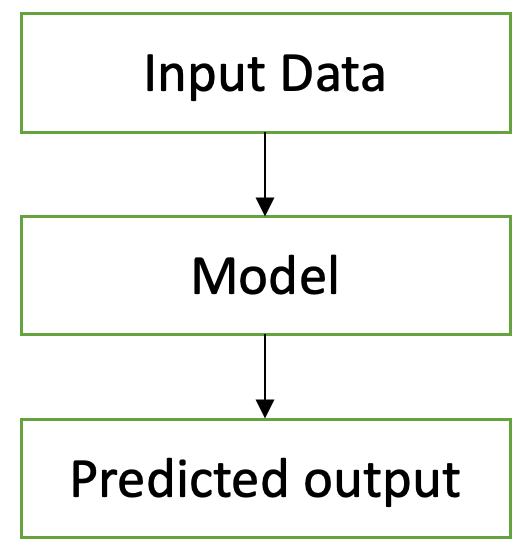
A real-world example for unsupervised learning could be to sift through login logs and detect anomalies. This helps you look for aberrations that you might not otherwise think of that hackers could exploit.
Another flavor of ML is RL or reinforcement learning. Here, the bot or agent you create makes predictions based on an algorithm or model. Call it trial and error. The agent is given feedback on what the right input should have been. In other words, there's a reward for the right output and a penalty for the wrong output. The agent is designed to continuously improve its model or algorithm to maximize rewards. A good example of this is training your dog, where successful execution of a command means a treat. Or, maybe the computer learns to play chess where the computer starts by being totally stupid, and as it loses, it learns not to make the same mistake again.
An even better example of reinforcement learning is self-driving, where the computer operates in shadow mode. It makes a prediction of what it might do under certain circumstances, but the human driver makes the actual moves. Those actual moves are compared constantly against the computer-predicted moves. If the computer's predictions match what the human would have done, it's considered a reward.
The real world is messy. What if the human was an awful driver? What if the computer could have driven safer than the human or had input the human can't see, such as radars, cognizance of six lanes around the car and four cars ahead and behind, data from other cars, that the human can't even see? Well, this is where you mix and match various approaches, along with the offline processing of data in the cloud.
Now you can see why Tesla ships autopilot hardware with every car. Whether or not you pay for autopilot, things still run in the background. The reinforcement data is uploaded into the cloud, and newer versions of autopilot software are constantly better than the last. This is mind-blowing stuff, really.
Speaking of the real world being messy, let's talk about deep learning, which is yet another important part of ML. Deep learning is a subset of machine learning that uses artificial neural networks to learn from data. Neurons are what make up the human nervous system. Artificial neural networks (ANNs) are inspired by our brains. Deep learning is made up of interconnected nodes called neurons. Each neuron receives input from other neurons and produces an output, and ANNs create layers upon layers of these neurons until the desired output is achieved.
These technologies are able to recognize complex patterns in data that would be hard for us to learn. And they do so using a combination of supervised and unsupervised learning. When we talk of the interesting applications of AI, such as image recognition, natural language processing, speech recognition, self-driving cars, medical diagnosis, fraud detection, and so on, these are all examples of deep learning.
Finally, let's talk about generative AI, which seems to be all the rage these days. Generative AI is a subset of deep learning. Generative AI, as the name suggests, generates content. All the stuff OpenAI has made news about lately, DALL-E, ChatGPT, etc., are examples of Generative AI. When you compose an email in Gmail or Outlook, and Gmail or Outlook prompt you to complete an email as you type, that's an example of Generative AI. As you give a small prompt to a document based on some input and a larger final and polished document is created, that's an example of generative AI.
You know that autocorrect on your touch screen phone? The one where you type and it predicts what the next word might be? That is also Generative AI in a rudimentary form.
Now we're getting somewhere. A great example of generative AI is large language models. Large language models, or LLMs for short, is an interesting field, which I feel will not only improve our touch-typing experience but also a lot more as well. Think about it. When you're typing “peanut butter and” and the automatically suggested word the phone shows is “jelly.” How did your phone predict that the next word is “jelly?” A lot of analysis has been done on English text, and apparently peanut butter and jelly is a thing, although some of you also like to have peanut butter and butter, and peanut butter and coffee, as can be seen in Figure 3. The computer knows it and prompts you to complete it accordingly.

I retried this experiment on Samsung and Google keyboards and was disappointed to see behavior not much more advanced than iOS. What if I were typing “jelly” but instead typed k and w (“kwlly”), which are characters right next to j and e on the keyboard? Why isn't the OS smart enough to guess that there's a high probability that I meant “jelly?” I distinctly remember Steve Jobs saying in one of Apple's keynotes that the keyboard is smart enough to judge such mistypes, but why don't I see it in action? Maybe it's too subtle.
Large Language Models
Large language models are a specific type of generative AI. They're trained on massive amounts of text data, which allows them to learn statistical relationships between words and phrases, and they're then able to generate text that's similar to the text they were trained on. LLMs can then subsequently be used for interesting applications, such as text generation, where, given specific context, you can generate blog posts, compose emails, etc. Or they can be used for translating between languages. They can be used to summarize large articles. Or they can be used to build Q&A bots. Or, the latest craze, chatbots, like ChatGPT or Bard. These are all examples of LLMs.
Now, the topic of generating an LLM is far beyond the scope of this article, and frankly it can get quite academic. One day, I'd love to get into the guts of it, but for the moment, here's the best part. When you use OpenAI, the hard work is all already done for you. Let's see that next.
OpenAI in Practice
So far, I've talked generally about the capabilities of AI and how we have reached where we are. As exciting as these concepts are, there are a few hurdles between us mere mortals and realizing the benefit of all this power for our applications. The hurdles are massive compute power, massive amounts of data, and well, huge brains on some really smart programmers.
All that stands between us and all this magic of AI is just some massive investment in compute, data, and huge brains. Lucky for us, OpenAI has done all of this. In fact, a subset of it is also exposed via Azure OpenAI. At the time of writing this article, Azure OpenAI is limited by invitation and private individuals, like me, can't use it. If you're part of a corporation, they will allow you to use it.
But, as a private individual, I can only go to www.openai.com and use the capabilities myself. On the other hand, Google has made some very amazing capabilities available in Google Cloud as well. I hope to write about them in a subsequent article. But for now, let's focus on OpenAI.
The first thing you need to do is visit www.openai.com and click on the “Sign up” button on the page. Once you log in, you'll see three choices. Note that this is a highly evolving space so their website may have changed by now. The choices are ChatGPT, DALL-E, or OpenAPI. You can also use ChatGPT on Bing.com or use DALL-E on bing.com/images/create. You can also use Google's equivalent of ChatGPT at bard.google.com.
Of the three choices presented, when you click on OpenAPI, you'll see a few choices. You'll see a quick-start tutorial, some examples, and the ability to build ChatGPT plug-ins. I'll focus on the API portion.
At https://platform.openai.com/examples, you'll see a number of examples you can play with. Looking at the code, an example, sample input, and sample output is free. To try things out for yourself, you're going to need a credit card.
On the top right-hand corner of the page, click on “upgrade,” and upgrade to a paid account. Now, because I'm the cheapskate that I am, I went to privacy.com and set up a throw-away credit card number, and I also set up a usage limit that's pretty low. Hey, don't judge me.
Okay, now I'm ready to play! You can pick any sample code and build it easily. For example, if I click on the “Grammar Correction” example, it shows me how to build it, as shown in Figure 4.
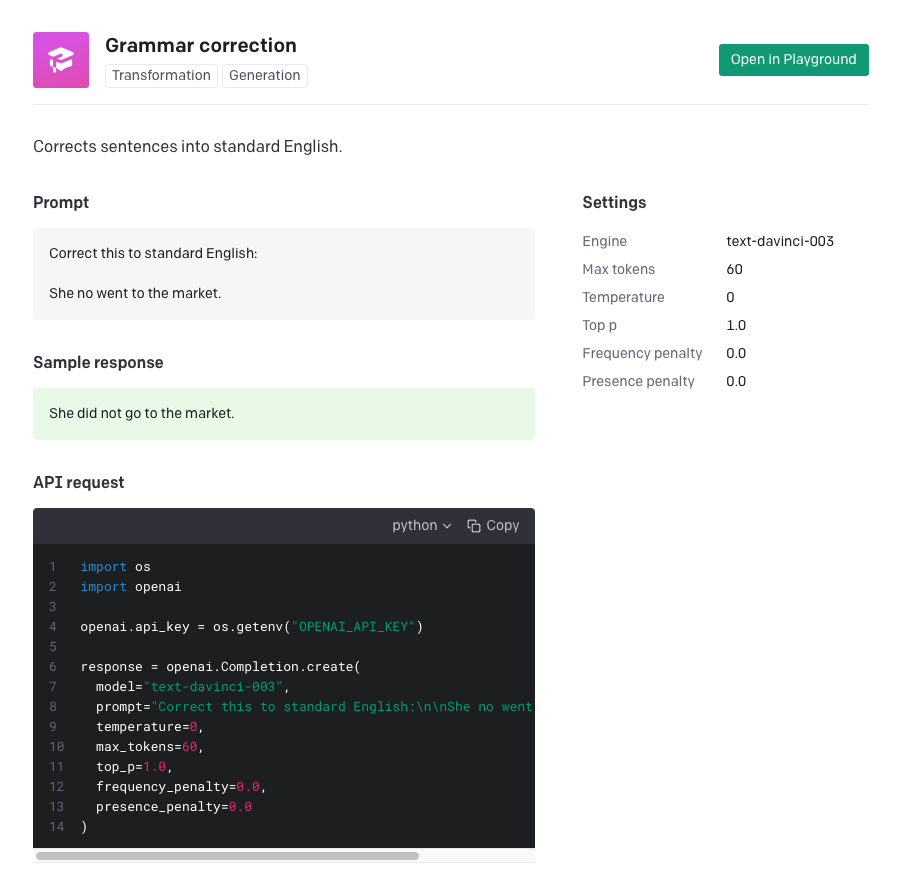
In fact, you don't even need to write this code. You can just try it out in the playground. Very well done, OpenAI! As a sidenote, I noticed that OpenAI's log-in process uses Auth0, and their interactive documentation also feels very much like Auth0's documentation. Very well done OpenAI.
Let's build something fun and from scratch. Something that's not in the examples.
Let's imagine, through an anomaly in time and space, I find myself as a student of quantum mechanics and I need to learn everything this chapter tells me: https://scholar.harvard.edu/files/david-morin/files/waves_quantum.pdf because tomorrow is exam day. I already feel like I'm time travelling back to college days. I seem to have spent the entire semester partying, and now, right before the exam, I'm just as unprepared and nervous as I used to be. But this time around, I have a secret weapon.
There are three main steps I need to do here.
First, I need to read up PDF as text and tokenize it. This text can be submitted to OpenAI APIs via the OpenAI SDK or as a simple REST call. I'll use the SDK.
The second thing to do is to create OpenAI embeddings. Embeddings are how OpenAI measures the relatedness of text strings. You can use it for various purposes, such as search, clustering, recommendations, anomaly detection, diversity measurement, and classification. It's essentially a vector of floating-point numbers, and the distance between two vectors measures their relatedness. Small distances mean high relatedness, and long distances mean low relatedness. Because this is a call to the API that's going to cost me money, I'll save the output locally.
The final step is to use this vector database and ask it questions in natural language. Figure 5 shows what I am trying to achieve.

Note: To run this code example is going to cost money. Not a lot, but don't say I didn't warn you.
The first thing you need to do is go to OpenAI and generate an API key at https://platform.openai.com/account/api-keys. There are many ways to configure your project to use API keys, and I choose to create a config.ini in my Python project, which can be seen here:
[API_KEYS]
OPENAI_API_KEY = <key here>
Now in my Python code, I can choose to read the API key, as can be seen in Listing 1.
Listing 1: Get the OpenAPI key
import os
import configparser
..
# Get the OpenAI API Key
config = configparser.ConfigParser()
config.read('config.ini')
os.environ["OPENAI_API_KEY"] = config.get('API_KEYS', 'OPENAI_API_KEY')
In my Python project, I'm going to take a dependency on a number of Python packages. These can be seen in my requirements.txt, as shown in Listing 2.
Listing 2. My requirements.txt
langchain
openai
tabulate
pdf2image
chromadb
tiktoken
Go ahead and install these requirements in your project using the command below:
pip install -r requirements.txt
Next in my app.py file, I'll choose to add some imports. I'm going to use them at various steps, so let's get this out of the way. My imports can be seen in Listing 3.
Listing 3: The imports my program depends on
import nltk
import os
import configparser
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain import OpenAI, PromptTemplate
from langchain.chains import RetrievalQA
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
The next step is to create embeddings. This is a two-step process. First, I need to read the PDF that I've saved locally and tokenize it. I'll use NLTK for tokenization and UnstructuredFileLoader from langchain.document_loaders for this purpose. Then I'll use CharacterTextSplitter to break this apart into manageable chunks. The end result should be a variable called “text,” which holds all the content I care about. Additionally, I don't want to do all this work multiple times. Once the embeddings are created, I want to save them and load them from the disk for the next execution. This first step of creating text chunks can be seen in Listing 4.
Listing 4: Create text chunks
vectordbPath = 'vectordb'
if not os.path.exists(vectordbPath):
# Load PDF
nltk.download("punkt")
loader = UnstructuredFileLoader('waves_quantum.pdf')
documents = loader.load()
# Create chunks
text_splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=0)
text = text_splitter.split_documents(documents)
Once I have the text chunks, I can create embeddings. This step is going to cost me money, so I want to save the output locally. This can be seen in Listing 5.
Listing 5: Create embeddings
embeddings = OpenAIEmbeddings(openai_api_key=os.environ["OPENAI_API_KEY"])
Chroma.from_documents(text, embeddings, persist_directory=vectordbPath)
Now that the embeddings are available as a local file, I can simply load them from the disk for subsequent runs and create a vectordb out of it. This can be seen in Listing 6.
Listing 6: Load local vectordb
embeddings = OpenAIEmbeddings()
vectordb = Chroma(persist_directory=vectordbPath,
embedding_function=embeddings)
Finally, I can start asking questions. This step also costs money, but there's no way around it. I've written a simple loop that allows the user to ask questions endlessly until the user types “exit.” This can be seen in Listing 7.
Listing 7: Ask questions
while True:
user_input = input(f"\nAsk question (or exit): ")
if user_input.lower() == 'exit':
break
else:
prompt_template = """
Context: {context} \n
Question: {question} \n
Answer:"""
prompt = PromptTemplate(template=prompt_template,
input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": prompt}
retriever = vectordb.as_retriever(
search_type="similarity",
search_kwargs={"k": 2})
qa_chain = RetrievalQA.from_chain_type(
OpenAI(temperature=0, max_tokens=400),
chain_type="stuff",
retriever=retriever,
chain_type_kwargs=chain_type_kwargs)
print('...thinking...')
response = qa_chain.run(user_input)
print(response, "\n")
That's it. Go ahead and run it and ask another difficult question. This time I asked, “What is an infinite square well?” The output can be seen in Figure 6. I already feel so smart.

This code example took me about 30 minutes to write. I ran it five or six times, and I want to share with you how much it cost me to do it. You can check your current usage at https://platform.openai.com/account/usage. I have shared my usage in Figure 7, and it looks like I spent six cents. I'll file an expense report.
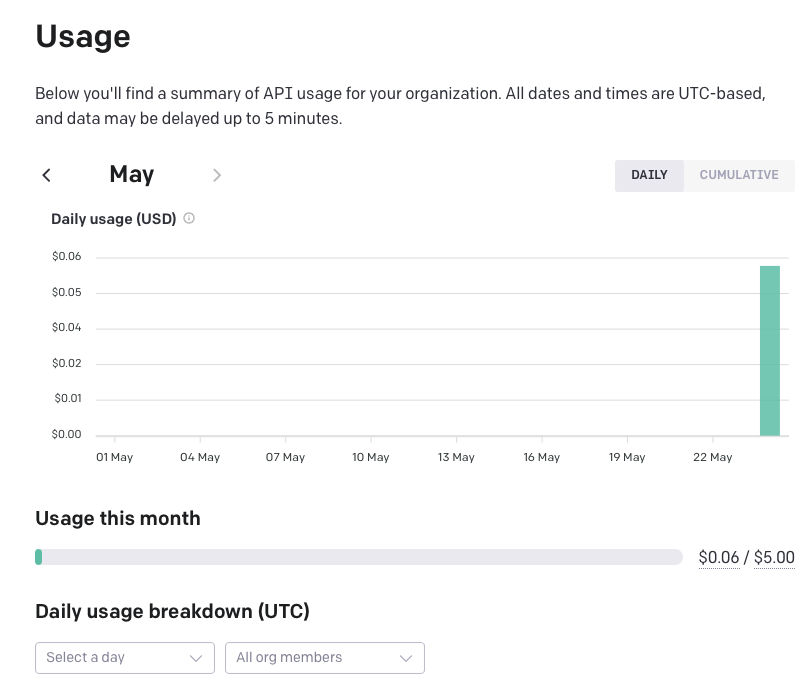
Jokes aside, there are a few things to keep in mind. These capabilities are impressive, but given the costs and limits on what I can consume, I wouldn't call this production-ready just yet. Also, there's a dependency on the cloud and personal identifying information (PII) concerns. Azure and Microsoft are working hard to fix all this, but they aren't quite there yet. Still, it's good to see what's possible and the pace of innovation here is quite furious. I'm sure, in almost no time, you'll be consuming OpenAI across your applications.
Summary
AI feels like a ground-breaking change, like the invention of the cell phone, personal computer, internal combustion engine, aviation, printing press, fire, etc. Is this hyperbole? Honestly, I don't think so. The applications of AI are only beginning to be apparent. As we move forward, not only will the capabilities of AI improve by leaps and bounds, but we'll start applying our creativity to solve problems with AI as well.
Pushing the boundaries of AI may remain the domain of large companies with deep pockets, but there are many LLMs that can be trained at the cost of a few hundred dollars or locally on your modern laptop. They aren't as good, but maybe they're good enough.
There will be many to options pick from. I certainly picked the right career because now, many years in, I'm yet to be bored in this line of work. For the very first time, I'm a bit scared of what this means for our society and our future.
How will you differentiate a real image from a fake in the upcoming election? How will you differentiate a real voice in a phone call from a loved one, vs. a computer-generated voice? As humans get displaced by computers learning so much faster than people, what will humans who simply cannot learn at the pace of computers do? Will the tools of AI be used for a distributed equitable benefit for the society, or will it fuel multi-million-dollar salaries for Silicon Valley elites?
There will be interesting times ahead. Until next time, let's keep learning.
