



Containers and container orchestrators have fundamentally changed the way we look at distributed systems. In the past, developers had to build these systems nearly from scratch, resulting in each architecture being unique and not repeatable. We now have infrastructure and interface elements for designing and deploying services and applications on distributed systems using reusable patterns for microservice architectures and containerized components.
Today's world of always-on applications and APIs have availability and reliability requirements that would have been required of only a handful of mission-critical services around the globe only a few decades ago. Likewise, the potential for rapid, viral growth of a service means that every application has to be built to scale nearly instantly, in response to user demand. These constraints and requirements mean that almost every application that's built, whether it's a consumer mobile app or a back-end payments application, would benefit from a distributed system. But building distributed systems is challenging.
Containerized building blocks are the basis for the development of reusable components and patterns that dramatically simplify and make accessible the practices of building reliable distributed systems. Reliability, scalability, and separation of concerns dictate that real-world systems are built out of many different components spread across multiple computers. In contrast to single-node patterns, multi-node distributed patterns are more loosely coupled. Although the patterns dictate communication between the components, this communication is based on network calls. Furthermore, many calls are issued in parallel, and systems coordinate via loose synchronization rather than tight constraints.
Microservice Architecture
Recently, the term microservices has become a buzzword for describing multi-node distributed software architectures. Microservices describe a system built out of many different components running in different processes and communicating over defined APIs. Microservices stand in contrast to monolithic systems like that in Figure 1, which tend to place all of the functionality for a service within a single, tightly coordinated application.
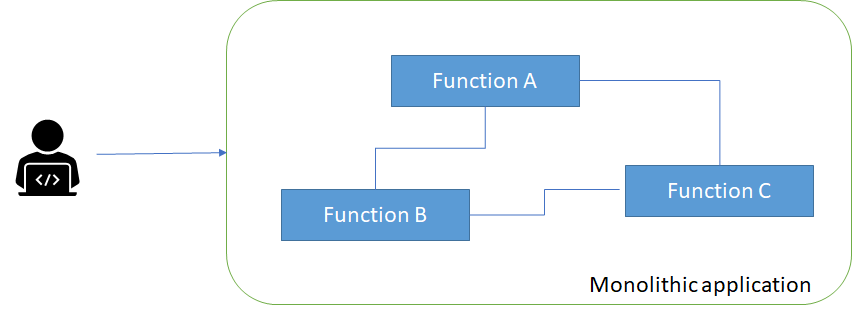
Figure 2, instead, illustrates how individual functions can be separated on isolated services and interact with each other through a programming interface (API).
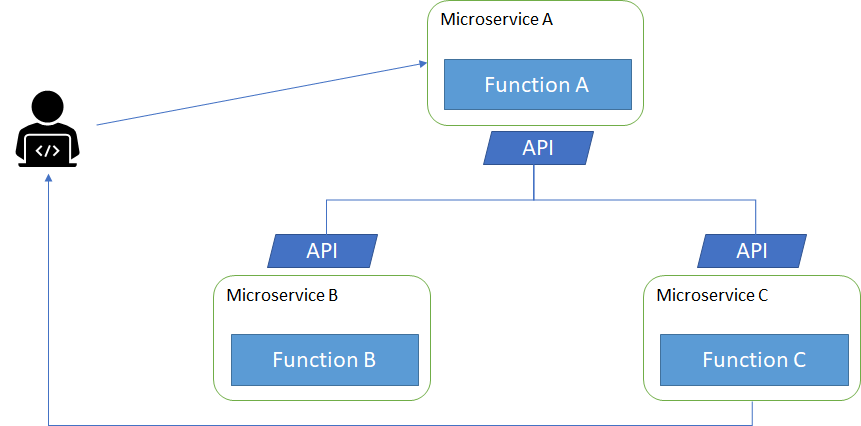
There are numerous benefits to the microservices approach, most of which are centered around reliability and agility. Microservices break down an application into small pieces, each focused on providing a single service. This reduced scope enables each service to be built and maintained by a single agile team. Reduced team size also reduces the overhead associated with keeping a team focused and moving in one direction.
Additionally, the introduction of formal APIs in between different microservices decouples the teams from one another and provides a reliable contract among the different services. This formal contract reduces the need for tight synchronization among the teams because the team providing the API understands the surface area that it needs to keep stable, and the team consuming the API can rely on a stable service without worrying about its details. This decoupling enables teams to independently manage their coding and release schedules, which, in turn, improves each team's ability to iterate and improve their function.
Finally, the decoupling of microservices enables better scaling. Because each component has been broken out into its own service, it can be scaled independently. It's rare for each service within a larger application to grow at the same rate or have the same way of scaling. Some systems are stateless and can simply scale horizontally, whereas other systems maintain state and require sharding or other approaches to scale. By separating each service out, you can use the approach to scaling that suits it best. This isn't possible when all services are part of a single monolith.
Azure Kubernetes Service
Kubernetes (https://kubernetes.io/) is a rapidly evolving platform that manages container-based applications and their associated networking and storage components. The focus is on the application workloads, not the underlying infrastructure components. Kubernetes provides a declarative approach to deployments, backed by a robust set of APIs for management operations.
You can build and run modern, portable, microservices-based applications that benefit from Kubernetes orchestrating and managing the availability of those application components. As an open platform, Kubernetes allows you to build your applications with your preferred programming language, OS, libraries, or messaging bus. Existing continuous integration and continuous delivery (CI/CD) tools can integrate with Kubernetes to schedule and deploy releases.
Azure Kubernetes Service (AKS: https://azure.microsoft.com/en-us/services/kubernetes-service/) provides a managed Kubernetes service that reduces the complexity for deployment and core management tasks, including coordinating upgrades. The AKS cluster masters are managed by the Azure platform, and you only pay for the AKS nodes that run your applications.
Figure 3 shows some basic components of a Kubernetes cluster architecture that's useful to get familiar with, before describing some typical design patterns for distributed systems and how to implement them in AKS. First of all, a Kubernetes cluster is divided into two components:
- Cluster master nodes that provide the core Kubernetes services and orchestration of application workloads.
- Nodes that run your application workloads.
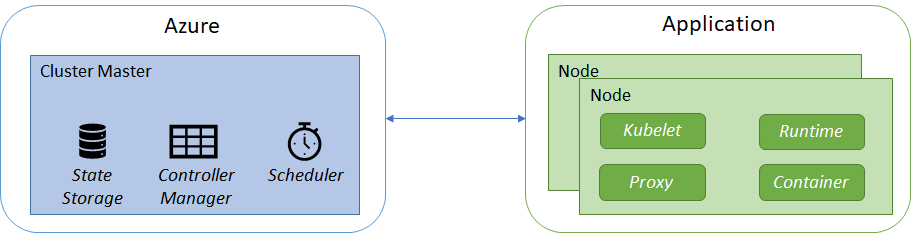
To run your applications and supporting services, you need a Kubernetes node. An AKS cluster has one or more nodes, which is an Azure virtual machine that runs the Kubernetes node components and container runtime. The kubelet is the Kubernetes agent that processes the orchestration requests from the cluster master and scheduling of running the requested containers. Virtual networking is handled by the proxy on each node. The proxy routes network traffic and manages IP addressing for services and pods (more about pods later in this article). The container runtime is the component that allows containerized applications to run and interact with additional resources, such as the virtual network and storage.
Replicated Load-Balanced Services
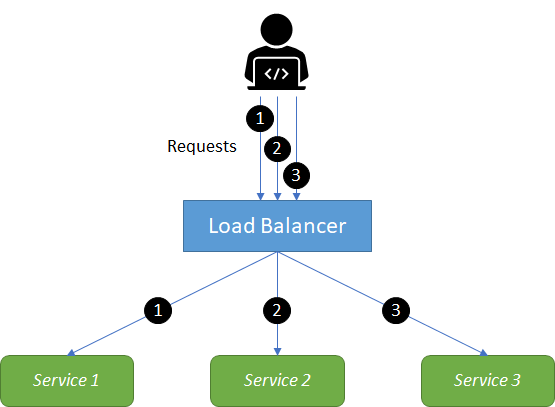
Replicated load-balanced services is probably one of the simplest distributed patterns, and one that most are familiar with when considering a replicated load-balanced application. In such an application, illustrated in Figure 4, every service is identical to every other service and all are capable of supporting traffic. The pattern consists of a scalable number of services with a load balancer in front of them. The load balancer is typically either completely round-robin or uses some form of session stickiness.
Stateless services are ones that don't require a saved state to operate correctly. In the simplest stateless applications, even individual requests may be routed to separate instances of the service. Stateless systems are replicated to provide redundancy and scale.
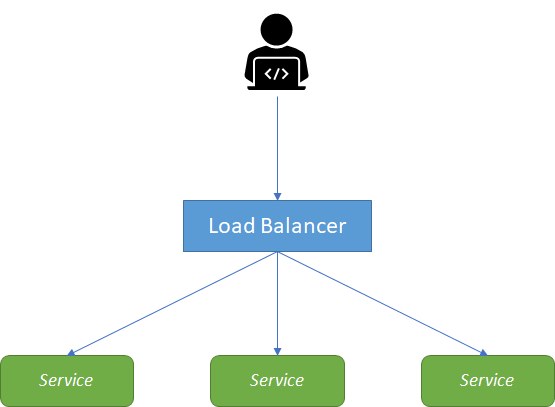
To create a replicated service in Azure Kubernetes Service, you can use the AKS virtual node to provision pods that start in seconds. With virtual nodes, you have fast provisioning of pods, and only pay per second for their execution time. In a scaling scenario, you don't need to wait for the Kubernetes cluster autoscaler to deploy VM compute nodes to run the additional pods. A Kubernetes pod is a group of containers that are deployed together on the same host. If you frequently deploy single containers, you can generally replace the word “pod” with “container” and accurately understand the concept.
If the resource needs of your application change, you can manually scale an AKS cluster to run a different number of nodes. When you scale down, nodes are carefully cordoned and drained to minimize disruption to running applications. When you scale up, AKS waits until nodes are marked ready by the Kubernetes cluster before pods are scheduled on them.
To scale the cluster nodes, first get the name of your node pool using the az aks show command. The following command gets the node pool name for the cluster named myCluster in the myResourceGroup resource group:
az aks show --resource-group myResourceGroup
--name myCluster
--query agentPoolProfiles
Then, use the az aks scale command to scale the cluster nodes. The following command scales a cluster named myAKSCluster to a single node. Provide your own –nodepool-name from the previous command:
az aks scale --resource-group myResourceGroup
--name myCluster --node-count 1
--nodepool-name <node pool name>
This is a way to manually scale an AKS cluster to increase or decrease the number of nodes. You can also use the cluster autoscaler (currently in preview in AKS) to automatically scale your cluster. The autoscaler component can watch for pods in your cluster that can't be scheduled because of resource constraints. When issues are detected, the number of nodes is increased to meet the application demand. Nodes are also regularly checked for a lack of running pods, with the number of nodes then decreased as needed. This ability to automatically scale up or down the number of nodes in your AKS cluster lets you run an efficient, cost-effective cluster.
To use the cluster autoscaler, you need the aks-preview CLI extension version 0.4.1 or higher. Install the aks-preview extension using the az extension add command, then check for any available updates using the az extension update command:
# Install the aks-preview extension
az extension add --name aks-preview
# Update the extension to make sure you have
# the latest version installed
az extension update --name aks-preview
It's not advisable to enable preview features on production subscriptions. Use a separate subscription to test preview features and gather feedback.
Scaling containers apply to increased or decreased workload, but also in response to scheduled application demands. For example, you may want to adjust your cluster between workdays and evenings or weekends. Figure 5 describes the two options for AKS clusters to scale:
- The cluster autoscaler watches for pods that can't be scheduled on nodes because of resource constraints. The cluster automatically increases the number of nodes.
- The horizontal pod autoscaler uses the Metrics Server in a Kubernetes cluster to monitor the resource demand of pods. If a service needs more resources, the number of pods is automatically increased to meet the demand.
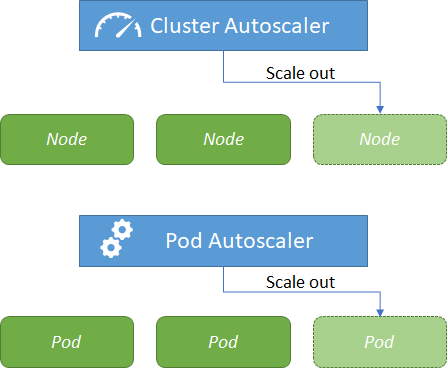
Both the horizontal pod autoscaler and cluster autoscaler can also decrease the number of pods and nodes as needed. The cluster autoscaler decreases the number of nodes when there has been unused capacity for a period of time.
Sharded Services
Replicating stateless services improves reliability, redundancy, and scaling. Within a replicated service, each replica is entirely homogeneous and capable of serving every request. Another design pattern emerges in contrast to replicated services, called sharded services. Figure 6 illustrates how, with sharded services, each replica, or shard, is only capable of serving a subset of all requests. A load-balancing node is responsible for examining each request and distributing each request to the appropriate shard for processing.
Replicated services are generally used for building stateless services, whereas sharded services are generally used for building stateful services. The primary reason for sharding the data is because the size of the state is too large to be served by a single ccomputer. Sharding enables you to scale a service in response to the size of the state that needs to be served.
Applications that run in Azure Kubernetes Service may need to store and retrieve data. For some application workloads, this data storage can use local fast storage on the node that is no longer needed when the pods are deleted. Other application workloads may require storage that persists on more regular data volumes within the Azure platform. Multiple pods may need to share the same data volumes or reattach data volumes if the pod is rescheduled on a different node. Finally, you may need to inject sensitive data or application configuration information into pods.
A good practice to reduce management overhead and let you scale is to not manually create and assign persistent volumes, as this would add management overhead and limit your ability to scale. The recommendation, instead, is to use dynamic storage provisioning by defining the appropriate policy to minimize unneeded storage costs once pods are deleted, and allow your applications to grow and scale as needed. Figure 7 refers to a persistent volume claim (PVC) that lets you dynamically create storage as needed. The underlying Azure disks are created as pods request them. In the pod definition, you request a volume to be created and attached to a designed mount path.
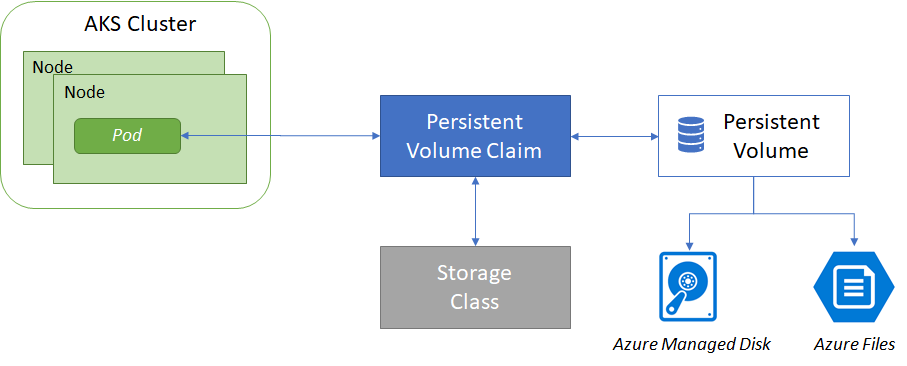
To define different tiers of storage, such as Premium and Standard, you can create a Storage Class. The Storage Class also defines the Reclaim policy. This Reclaim policy controls the behavior of the underlying Azure storage resource when the pod is deleted, and the persistent volume may no longer be required. The following example uses Premium Managed Disks and specifies that the underlying Azure Disk should be retained when the pod is deleted:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: managed-premium-retain
provisioner: kubernetes.io/azure-disk
reclaimPolicy: Retain
parameters:
storageaccounttype: Premium_LRS
kind: Managed
You can create a persistent volume claim with the kubectl apply command and specify the YAML file containing the configuration parameters:
$ kubectl apply -f azure-premium.yaml
persistentvolumeclaim/azure-managed-disk created
A persistent volume represents a piece of storage that has been provisioned for use with Kubernetes pods. A persistent volume can be used by one or many pods and can be dynamically or statically provisioned. As written before, a storage class is used to define how a unit of storage is dynamically created with a persistent volume. For more information on Kubernetes storage classes, see Kubernetes Storage Classes (https://kubernetes.io/docs/concepts/storage/storage-classes/). The following command shows the pre-created storage classes available within an AKS cluster:
$ kubectl get sc
NAME PROVISIONER AGE
default (default) kubernetes.io/azure-disk 1h
managed-premium kubernetes.io/azure-disk 1h
Modern application development often aims for stateless applications, but stateful sets can be used for stateful applications, such as applications that include database components. A StatefulSet is similar to a deployment in that one or more identical pods are created and managed. Replicas in a StatefulSet follow a graceful, sequential approach to deployment, scale, upgrades, and terminations. For more information, see Kubernetes StatefulSets (https://kubernetes.io/docs/concepts/workloads/controllers/statefulset).
Scatter-Gather Pattern
So far, I've examined systems that replicate for scalability in terms of the number of requests processed per second (the stateless replicated pattern), as well as scalability for the size of the data (the sharded data pattern). The scatter-gather pattern in Figure 8 uses replication for scalability in terms of time and allows you to achieve parallelism in servicing requests, enabling you to service them significantly faster than you could if you had to service them sequentially.
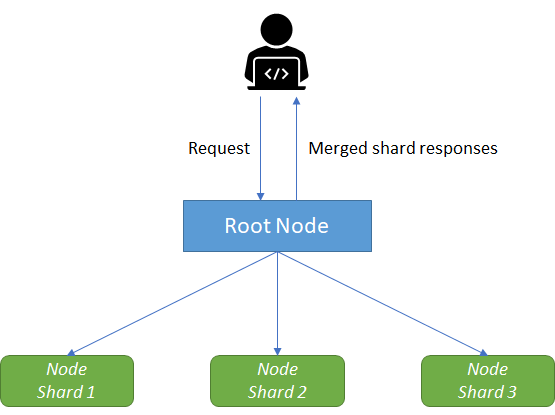
Like replicated and sharded systems, the scatter-gather pattern is a tree pattern with a root that distributes requests and leaves that process those requests. However, in contrast to replicated and sharded systems, scatter-gather requests are simultaneously farmed out to all of the replicas in the system. Each replica does a small amount of processing and then returns a fraction of the result to the root. The root server then combines the various partial results together to form a single complete response to the request and then sends this request back out to the client.
Scatter-gather is quite useful when you have a large amount of mostly independent processing that's needed to handle a particular request. This pattern can be seen as sharding the computation necessary to service the request, rather than sharding the data (although data sharding may be part of it as well).
To see an example of scatter-gather in action, consider the task of searching across a large database of documents for all documents that contain the words “car” and “Ferrari.” One way to perform this search is to open up all of the documents, read through the entire set searching for the words in each document, and then return the set of documents that contain both words to the user. As you might imagine, this is quite a slow process because it requires opening and reading through a large number of files for each request. To make request processing faster, you can build an index. The index is effectively a hashtable, where the keys are individual words (e.g., “car”) and the values are a list of documents containing that word.
Now, instead of searching through every document, finding the documents that match any one word is as easy as doing a lookup in this hashtable. However, one important ability was lost. Remember that you were looking for all documents that contained “car” and “Ferrari.” Because the index only has single words, not conjunctions with words, you still need to find the documents that contain both words. Luckily, this is just an intersection of the sets of documents returned for each word. Given this approach, you can implement this document search as an example of the scatter-gather pattern. When a request comes in to the document search root, it parses the request and farms out two leaf computers (one for the word “car” and one for the word “Ferrari”). Each of these computers returns a list of documents that match one of the words, and the root node returns the list of documents containing both terms.
