


This excerpt is from the book, C# 4.0 Unleashed, authored by Bart De Smet, published Jan 4, 2010 by SAMS and is part of the Unleashed series. ISBN 0672335522, Copyright 2011. For more info, please visit the publisher site http://www.informit.com/store/product.aspx?isbn=0672330792.
In This Chapter
- The Evolution of C#
- A Sneak Peak at the Future
Loaded with a basic understanding of the .NET platform and its philosophy, we’re ready to dive in to one of its core languages: C#. To set the scene, this chapter starts by looking at the evolution of the C# language throughout the first four releases of the .NET Framework. As we cover the four versions of the language, core language features and design themes will be highlighted.
Next, we take a look at the challenges that we’ll face in the near future. At the end of this chapter, you’ll understand the forces that have shaped the language covered in depth throughout the remainder of the book. In the next chapter, we switch gears and explore the tooling support available to develop on the .NET Framework using C#.
The Evolution of C#
In this book, we explore the .NET Framework from the C# developer’s perspective, focusing on the various language features and putting them in practice with a wide range of libraries that ship in the Base Class Library (BCL) or as part of separate software development kits (SDKs). But before we do so, let’s take a quick look at the various C# releases and what has shaped the language into what it is today, the .NET Framework 4. Figure 2.1 highlights the important themes that defined the evolution of C# so far.
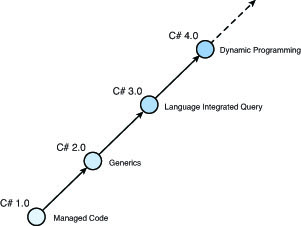
C# 1.0: Managed Code Development, Take One
Creating a new runtime is one thing; providing a rich set of libraries to make the technology relevant is another thing-moreover, it’s the most crucial thing developers care about when deciding whether to embrace a new platform.
This put a big task on the shoulders of Microsoft’s .NET Framework BCL team, having to write code targeting a runtime that was still under development. Obviously, one of the core ingredients to make this mission successful was to have a programming language and compiler-not to mention productivity tools such as debuggers-readily available to get the development going.
Only two options were available. One was to retrofit an existing language like C++ or Visual Basic on the .NET platform. Although this was in line with the whole vision of the Common Language Infrastructure (CLI), it had its downsides. Porting languages, preserving semantics, and potentially introducing lots of backward-compatibility requirements early on didn’t seem an attractive option under the pressure to get BCL development off the ground as soon as possible.
As you might have guessed by now, the second option was to come up with a brand new language. Such a language wouldn’t have to care about preserving backward compatibility and could expose the richness of the Common Type System (CTS) in a no-nonsense way, mapping language features directly onto their CTS counterparts. This marked the inception of project Cool, which stood for “C-style Object-Oriented Language,” later to be renamed to C# (pronounced “see sharp”).
Design and implementation of C# began in late 1998, led by Anders Hejlsberg. He previously worked at Borland designing the highly successful Turbo Pascal and Delphi products and later joined Microsoft to work on J++ and Windows Foundation Classes (WFC) and, more recently, on C# and the rest of the Microsoft-managed programming languages. Other core language design members were Scott Wiltamuth, Peter Golde, Peter Sollich, and Eric Gunnerson.
The origin of the name C#
Although Cool was a rather, let’s say, cool name, marketing folks wanted a different branding for the new language. The C part in the name was a straightforward choice, given that the language embraced C-style syntax, with curly braces, types in front of names, and so on.
Because the new language was considered to allow a more modern approach to object-oriented programming with type safety as its cornerstone, having the name imply a degree of superiority to C++ (which was not designed with type safety as a central theme) was desirable. Because the name C++ comes from the post-increment ++ operator applied to regular C, one option would have been to follow along that theme. Unfortunately, C++++ is not syntactically correct (C+ = 2 would be too ridiculous), and moreover, the new language did not intend to become a superset of C++.
So some brilliant mind came up with a postfix notation that has a meaning of “higher than” but from a totally different domain: music notation. I’m not a musician myself, but my office mate (thanks, Mike) reassured me the official definition of the sharp sign (#) is to indicate “half a tone higher” on the note that precedes it. Lucky coincidence or not, the sharp sign looks a lot like two post-increment operators stacked on top of each other.
To keep typing the language’s name simple, the sharp sign is not written as Unicode character U+266F (#) but as the number sign U+0023 (#) instead. The pronunciation is “see sharp,” though.
Personally, I like the name C# a lot. For one thing, it definitely sounds better than Managed C++, C++/CLI, or C++0x (no pun intended). Also, the use of the sharp sign in programming language names has become some kind of trademark of the .NET Framework, with the newborn F# language and the Spec# research project (a predecessor to code contracts in .NET 4.0). And just for the sake of it, my blog is known as B# (cheesy, I know).
References have been made to the meaning of the sharp sign in various places. At some point, there was a research project called Polyphonic C# that explored the area of concurrent programming using “chords.” (I won’t go into detail on this right now.) Another project was CW (“see omega”), which used the last letter in the Greek alphabet, omega, to indicate its rich extensive nature over C#. Technologies like LINQ in C# and Visual Basic and XML literals in Visual Basic originate from this project.
For some unknown reason, the dynamic language folks didn’t get chased by the marketing department for choosing names with the “Iron” prefix, like IronPython and IronRuby. Maybe because the use of metals in product names has precedents (think of Silverlight) or perhaps because they did get away with the claim it stands for “I Run On .NET.”
So what were the design themes of the C# language right from the start? There’s no better quote than the introductory sentence of the official C# specification, which is standardized in ECMA 334:
C# is a simple, modern, object-oriented, and type-safe programming language. C# has its roots in the C family of languages and will be immediately familiar to C, C++, and Java programmers.
Let’s analyze those claims in a bit more detail:
- Simplicity matters. C# deliberately does away with language features that are known to cause developers headaches, such as multiple inheritance, fall-through behavior in switch statements, and nonhygienic macros.
- Modern is good. It means the language recognizes concepts developers are directly familiar with, such as properties, events, and more recently, data querying, even though “pure” object-oriented languages don’t need those.
- Object-oriented programming was, and still is, a widely accepted proven technique to master complexity in worlds where tons of software components need to work together seamlessly. No wonder the CLI and C# embrace it.
- Type safety is a big thing in the CLI. It eliminates whole classes of bugs and security headaches that plague languages like C and C++. This said, C# still allows type-unsafe code in regions explicitly marked as such.
- Having roots in the C family of languages makes the learning curve to get into C# easy for developers who’ve been using C or any of its derivatives in the past.
- With its rich feature set, great tooling support in Visual Studio .NET version 2002, and backed by the rich BCL in .NET Framework 1.0, C# programming took a jumpstart. However, the language designers were a long way from running out of ideas.
Visual or not?
If you browse the Microsoft Developer Network (MSDN) website, you’ll often see references to Visual C# rather than just C#. What’s the correct name? It depends what you’re talking about: The language name simply is C#, whereas the development tool Microsoft provides to develop with the language is called Visual C#, after the Visual Studio tooling family it’s part of. A notable exception to this rule is Visual Basic, where both the language and the product name are the same.
C# 2.0: Enriching the Core Language Features
Shipping a first release of a brand new platform and language was key to getting the ball rolling, so sometimes decisions had to be made to cut certain features during the development of this first release. The second release of the .NET Framework allowed the opportunity to catch up with the things the design teams wanted to do but hadn’t gotten a chance to in the first release.
Backward compatibility matters
Making sure code written using a previous release of the language doesn’t compile anymore-or worse, starts behaving differently-is an essential design criterion when evolving the language.
C# is strict about this and aims to keep new releases of the language 100% compatible with older versions. You might wonder how this is possible when introducing new language features that potentially require new keywords. The answer lies in contextual keywords.
Right from the start, C# has had contextual keywords. It simply means a certain word can be treated as a keyword in certain contexts, while it can be used as an identifier in others. A good example of such a keyword is value. In the following fragment, it’s used as a keyword within the property set accessor to denote the value being set:
public string Name
{
get { return _name; }
set { _name = value; }
}
However, when used outside the scope of a property setter, value can be used as a regular identifier, as follows:
static void Main()
{
int value = 42;
Console.WriteLine(value);
}
When C# 2.0 came around, new keywords were required to enable certain features. All those newly introduced keywords were implemented to be contextual, so they can’t clash with existing names used in the program. As an example, generics support the specification of constraints on generic parameters using the where keyword:
static void Sort<T>(List<T> items) where T : IComparable
{
// Generic sort algorithm
}
In code written before C# 2.0, it was simply impossible to use where in such a context, so there’s no risk of breaking something here. Also, by making the keyword contextual, it can still be used as an identifier outside this context:
static void Main()
{
string where = “There”;
Console.WriteLine(where);
}
Later, when C# 3.0 came around (see further), query expressions were added to the language. To express a filtering clause in a query, it simply makes sense to use the where keyword (SQL, anyone?) but in another context:
var res = from person in db.People
where person.Age > 25
select person;
Again, contextual treatment for keywords saves the mission.
So why did C# 1.0 have contextual keywords if there was no chance of breaking existing code? Well, it’s a convenience not to have to escape “common words” just because they tend to have a special meaning in certain locations. The value keyword is a great example of that, but the same holds for get and set. Sometimes I wish this were applied more aggressively, making keywords such as class contextual, too. Having developed a system for school administration in a past life, I can assure you that the use of the word class as an identifier was a rather natural choice to refer to an object representing, um, a class. Luckily, C# has an escape mechanism for such cases:
MyClass @class = new MyClass();
To finish this point, if you ever find a piece of code that did compile in an older version of the language but doesn’t anymore, you most certainly have found a defect. Beware, though, that application programming interfaces (APIs) are a bit more relaxed when it comes to changing behavior over time. This is typically done by deprecating certain API members, making developers aware that a particular part of the API might go away in future releases. We should consider ourselves lucky that the C# language has been spared from this deprecating business thanks to careful design.
Generics
.NET Framework 2.0 came with a major update to the common language runtime, mainly to add support for generics to the type system. Generics were prototyped in a project code named Gyro run by Don Syme (later to become the creator of F#) and Andrew Kennedy, both working at Microsoft Research. Such a fundamental addition to the type system required revisions of the languages that build on top of it. Therefore, both the C# and Visual Basic .NET languages were enhanced to provide support for both declaring and consuming generic types.
To support the introdution of generics, the BCL team added various generic collection types to the System.Collections.Generic namespace, an example of which is illustrated in the code fragment here:
List<int> primes = new List<int>();
for (int n = 2; n <= 100; n++)
{
bool isPrime = true;
for (int d = 2; d <= Math.Sqrt(n); d++)
{
if (n % d == 0)
{
isPrime = false;
break;
}
}
if (isPrime)
primes.Add(n); // statically typed to take in an integer value
};
// no performance hit to convert types when retrieving data
foreach (int prime in primes)
Console.WriteLine(prime);
Generics offer better static typing, thus doing away with whole classes of code defects and various performance benefits because they eliminate the need for runtime type conversions.
Nullable Types
During the design of the first release of the CLI, a distinction had been made between value types and reference types. Value types are stack allocated, whereas reference types live on the managed heap. Therefore, reference types can have null values (conceptually comparable to null pointers in native languages), whereas value types cannot.
The lack of an orthogonal approach in the classification of types versus their nullability was seen as an oversight that was rectified in the second release of .NET Framework with the introduction of nullable value types. This proves especially handy when mapping database records to objects because nullability applies to all types in the world of (relational) databases.
The following is an example of the use of nullable types, denoted with a ? suffix:
int a = null; // won’t compile; int is a value type and cannot be set to null
int? b = null; // valid in C# 2.0 and above
Note
The use of the ? suffix comes from the world of regular expressions where it is used to indicate “zero or one” occurrences of the thing preceding it. The ? operator is one of the Kleene operators used to indicate multiplicity. Other Kleene operators include * (zero or more) and + (one or more), but corresponding language features do not exist in the world of C#.
The ? notation is a form of syntactic sugar, meaning it’s shorthand syntax for a construct that would be tedious to type every time again. T? simply stands for Nullable<T>, a generic type, where T is required to be a value type. In the preceding example, we could have written int? as Nullable<int>, but you’ll agree that’s quite some typing to express such a simple concept, hence the justification to provide syntactic sugar.
Oh, and by the way, contrary to popular belief, nullable value types are not just a language-level feature. Some of the runtime’s instructions have been enlightened with knowledge about this type to accommodate for better integration.
Iterators
Although generics and nullable types can be seen as features to catch up with everything the design team wanted to do in .NET 1.0 but didn’t get to because of the need to get the first release out of the door, C# 2.0 introduced a few language features that reduced the amount of plumbing required to express conceptually simple pieces of code. We can consider this to be the tip of the iceberg on our journey toward a more declarative style of programming.
One such feature is called an iterator and allows the creation of code blocks that produce data on demand. This introduces a form of lazy evaluation in the language. An example of an iterator declaration is shown here:
static IEnumerable<int> LazyPrimes()
{
for (int n = 2; n <= int.MaxValue; n++)
{
bool isPrime = true;
for (int d = 2; d <= Math.Sqrt(n); d++)
{
if (n % d == 0)
{
isPrime = false;
break;
}
}
if (isPrime)
yield return n; // Yield primes to the caller one-by-one
};
}
The use of the yield keyword controls the iterator’s behavior. If the consumer requests an iterator to produce a value, it runs until a yield statement is encountered. At that point, the iterator is suspended until the consumer asks for the next value. In the preceding example, we’ve declared an iterator that can produce all integer primes (within the range of positive 32-bit signed integer values). How many primes are calculated is completely under the control of the consumer, as shown here:
foreach (int prime in LazyPrimes())
{
Console.WriteLine(prime);
Console.Write(“Calculate next prime? [Y/N] “);
char key = Console.ReadKey().KeyChar;
if (char.ToLowerInvariant(key) != ‘y’)
break;
Console.WriteLine();
}
If the user stops requesting prime numbers, the iterator will never go through the burden of calculating more primes than were ever requested. Contrast this with an eager evaluation scheme, where a whole bunch of primes would be calculated upfront and stored in some ordered collection for return to the caller.
Manual creation of an iterator-without the yield keyword, that is-is an extremely painful task because of its need to support suspension and subtleties that arise with multithreading, multiple consumers, and proper cleanup of used resources. Not only that, the resulting code would look nowhere near the one we get to write with C# 2.0; the meaning of the iterator would be buried under lots of plumbing, making the code hard to understand.
C# alleviates this task by making the compiler generate all the boilerplate code required to build an iterator. This is just one example of a feature that makes the language more declarative, allowing developers to just state their intent, leaving the implementation details to the language and runtime, also reducing the risk of introducing subtle bugs.
Iterators are essential glue for the implementation of a C# 3.0 feature, LINQ to Objects. We get to that in just a minute.
Note
I consider another feature called closures to fall under the umbrella of “convenience features” too. Because this feature is much more obscure, I’m omitting it from this discussion, except to say that it provides essential glue to allow for seamless use of some functional programming constructs within the language.
Again, the C# compiler takes responsibility over a lot of plumbing that would be imposed on the poor developer otherwise. We cover closures in detail when discussing the use of delegates and anonymous methods.
C# 3.0: Bridging the Gap Between Objects and Data
In some regard, C# 3.0 was the first release where the language designers got a real chance to think deeply about the everyday problems developers face when writing real-world code. Project Clarity identified one such problem, dealing with the impedance mismatch between object-oriented programming and accessing data stores of various kinds.
Language Integrated Query
One problem developers face when dealing with data access is the wide range of data storage technologies: in-memory object graphs, relational databases, Extensible Markup Language (XML) data, and so on. Each of those stores has its own API that’s different enough from the others to throw developers a learning curve each time a different type of data store is encountered. A way to unify those APIs was much desired, and that’s exactly what Clarity stood for.
When this vision became real, the project was renamed Language Integrated Query, or LINQ. It enables developers to use built-in language syntax to target any data store that has a LINQ provider for it, as illustrated here:
var res = from product in db.Products
where product.Price > 100
orderby product.Name
select new { product.Name, product.Price };
Note
Similar language support was added to Visual Basic 2008. Also, LINQ has more query operators than the languages surface; regular method calls can be used to take advantage of these additional query operators.
The conceptual diagram depicting the relationship between languages and underlying query providers is shown in Figure 2.2.
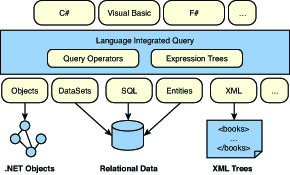
In addition to providing a unified query language, this approach has many additional benefits. For example, it provides strong typing over the target domain, allowing for compile-time checking of the soundness of queries. In addition, the LINQ provider libraries can make sure queries are built correctly to eliminate whole classes of errors, including security breaches such as SQL injection attacks.
This type of programming reflects the desire to move toward a more declarative style of programming, where developers yield control to the language, runtime, and libraries. By doing so, the platform as a whole can “reason” about the developer’s intent and do the right thing, potentially optimizing the execution on behalf of the developer.
Note
Almost all of today’s computers have multiple processor cores, allowing for true parallelism. Imperative programming techniques do not scale well to write concurrent programs for various reasons. Besides the need for low-level concurrency programming using locks and other synchronization primitives (which are very hard to deal with), we typically overspecify the solution to a problem. Instead of just expressing what we want done, we also specify-in excruciating detail-how we want it done, using a bunch of imperative constructs such as if statements, loops, and so on. By doing so, we paint the runtime out of the picture, leaving it no other choice but to execute our imperative program exactly as we’ve written it.
Manual parallelization of query-like constructs written in an imperative style (nested for loops with a bunch of if statements and extensive use of intermediate data structures) would be a grueling and very error-prone experience for developers. However, in the world of declarative programming, the runtime is left with enough knowledge about our intent for it to optimize the execution. Today, with LINQ, this is no longer a dream: A parallelizable version of LINQ to Objects has been created, dubbed PLINQ, which ships in .NET Framework 4. The more cores the user has in her machine, the faster the query executes. Mission accomplished.
Today, a wide variety of LINQ providers are available. Microsoft provides LINQ to Objects (to deal with in-memory data), LINQ to XML, LINQ to DataSets, LINQ to SQL, and LINQ to Entities (to deal with relational databases), and we can expect many more in the years to come. In addition, lots of third parties have developed LINQ providers that target nearly anything queryable out there: Amazon, Flickr, SharePoint, Active Directory, to name just a few.
The introduction of LINQ in C# reflects the language’s practical nature, solving real-world problems developers are facing. But the design of LINQ yielded many benefits beyond the domain of querying, too. On the surface, it looks like LINQ forms a foreign island in an otherwise imperative language, but in reality it’s built out of an amalgam of smaller language features that provide benefits in and of themselves, too. Let’s look at those features briefly.
Local Variable Type Inference
The introduction of generics in .NET 2.0 is all goodness but has one dark side: Type names can grow arbitrarily because type parameters can be substituted for any type, including other generic types. An example concretizes this:
Dictionary<string, List<PhoneNumber>> whitePages =
new Dictionary<string, List<PhoneNumber>>();
Wait a second: Doesn’t this line state the type twice? Indeed, on the left, the type is used to declare a variable, and on the right, it’s used to instantiate an instance of it. The code snippet doesn’t even fit on a single line because of this duplication. With local variable type inference, you can omit the type on the left side, substituting it with the var keyword and letting the compiler figure out the type for you based on the right side:
var whitePages = new Dictionary<string, List<PhoneNumber>>();
Although we can drop the type in the declaration of the local variable, this code is still strongly typed. The compiler knows exactly what the type is, and the emitted code is exactly as if you had written out the type yourself.
By itself, local variable type inference is useful for reducing the syntactic noise that comes with the use of generic types, where it’s just a nicety to have. However, in some cases, local variable type inference is required, as you’ll see next.
Anonymous Types
The desire to integrate query capabilities in the language introduces the need to have an easy way to construct types on-the-fly. Projections (the select clause in a LINQ query) are the most obvious places where this need becomes apparent.
var res = from product in db.Products
where product.Price > 100
orderby product.Name
select new { product.Name, product.Price };
Having to declare an explicit type for each projection would put quite some burden on developers using LINQ. In the example, the compiler synthesizes an anonymous type with properties Name and Price as specified in the projection.
The reason we call those types “anonymous” is because the compiler generates an unspeakable name for them. Because we can’t refer to them, we need help from the compiler to infer their names when assigning them to local variables. In the preceding example, the result of the query was assigned to an implicitly typed local variable, letting the compiler figure out its type.
Initializer Expressions
To make the initialization of collections and objects easier, C# 3.0 introduces initialization expressions for both. Let’s take a look at them.
Object initializers make the instantiation of a type followed by setting a bunch of its public properties (or public fields) easier to do, as part of one single expression. This proves particularly useful when the type you want to instantiate lacks an appropriate constructor:
class Product
{
public Product(string name)
{
Name = name;
}
public string Name { get; set; }
public decimal Price { get; set; }
}
In C# 2.0, you would have to write the following to create an instance of this type, with both Name and Price set:
Product p = new Product(“Chai”);
p.Price = 123.45m;
With object initializer syntax, this can be abbreviated as follows:
Product p = new Product(“Chai”) { Price = 123.45m };
Note
To be precise, the code generated for an object initializer expression is slightly different from the C# 2.0 snippet shown above it. We’ll ignore this detail now and defer a more in-depth discussion until Chapter 6, “A Primer on Types and Objects.”
Object initializers are typically used in the projection clause of LINQ queries, when an existing type is available (contrast this to the case where no type is available but an anonymous type can be used) but lacks an appropriate constructor:
var res = from product in db.Products
where product.Price > 100
orderby product.Name
select new Product(product.Name) { product.Price };
Collection initializers bring simple initialization syntax to generic collection types. Since the very beginning of C#, it has been possible to initialize arrays simply by specifying the elements in between curly braces like this:
int[] primes = new int[] { 2, 3, 5, 7 };
However, when using generic collections like List<T> in C# 2.0, this nice syntax was no longer possible. Instead, you had to write the following:
List<int> primes = new List<int>();
primes.Add(2);
primes.Add(3);
primes.Add(5);
primes.Add(7);
With C# 3.0, you get to write this (notice the nonmandatory use of local variable type inference):
Note
Observe how collection initializers and object initializers can be combined nicely when initializing collections of rich types. Another “better together” story.
Extension Methods
Extension methods enable you to extend existing types without using inheritance and thus allow methods to be added to any kind of type. For example, suppose you want to add a Reverse method to the System.String type that comes in the BCL. The best you could do before C# 3.0 was to create a static helper method, making it rather cumbersome to use:
static class Helpers
{
public static string Reverse(string s)
{
char[] characters = s.ToCharArray();
Array.Reverse(characters);
return new string(characters);
}
}
static class Program
{
static void Main()
{
string name = “Bart”;
string reverse = Helpers.Reverse(name);
Console.WriteLine(reverse);
}
}
With extension methods, we can allow the static method to be used as if it were an instance method:
string reverse = name.Reverse();
To enable this, the first parameter of the Reverse method is marked with the this keyword, turning it in an extension method:
public static string Reverse(this string s)
LINQ uses extension methods to add query operators to interfaces like IEnumerable<T> and IQueryable<T>.
Note
Extension methods allow the design and use of “fluent” APIs. A good example of a fluent API is the System.String type: Most of its methods return a System.String instance, allowing the next method to be called immediately, like so:
string bart = “ Bart “;
string art = bart.ToUpper().Trim().Substring(1); // ART
Without extension methods, any attempt to “chain in” another operation in the middle broke the fluency of the code:
string bart = “ Bart “;
string tra = Helpers.Reverse(bart.ToUpper().Trim()).Substring(1); // TRA
It takes a few reads to figure out the order of operations in the preceding code fragment. Thanks to extension methods, the preceding code can be made fluent again:
string bart = “ Bart “;
string art = bart.ToUpper().Trim().Reverse().Substring(1);
One great example of such a fluent API is LINQ itself, as you’ll see later on.
Lambda Expressions
Although C# has been an imperative object-oriented programming since the very beginning, language paradigms have been added over the years. One such paradigm is functional programming, the ability to write programs based on the use and definition of mathematical function.
Note
In fact, one of the key enablers for functional programming in C# was added in the second release of the language: closures. We won’t go into details right now, except to say that turning programming paradigms into first-class citizens in an existing language often takes more than one feature.
Lambda expressions are simply that: definitions of functions, but in a very concise form with little syntactical ceremony. Because the underlying platform supports delegates as a way to pass pieces of code around, lambda expressions can leverage this infrastructure and be converted into delegates. The following example illustrates the creation of a function that adds two numbers together, with and without the use of lambda expressions:
// C# 2.0 style
Func<int, int, int> add20 = delegate (int a, int b) { return a + b; };
// C# 3.0 style
Func<int, int, int> add30 = (a, b) => a + b;
The Func<T1, T2, R> type used in this example (with all parameters substituted for int) is a generic delegate for a function that takes in something of type T1 and T2 and returns something of type R. Its definition looks like this:
delegate R Func<T1, T2, R>(T1 arg1, T2 arg2);
Where the name lambda comes from
Where the heck does a fancy name like lambda come from? The answer lies in the lambda calculus, a mathematical framework to reason about functions, developed in 1928 by Alonzo Church. Lambda is actually a Greek letter, λ, and happened to be chosen to name the theory. (Other calculi named after Greek letters exist, such as the Pi calculus, which is used in the domain of parallel computing.)
It took about 30 years for this mathematical foundation to be applied in the domain of computer science. LISP (due to McCarthy) was created in 1958 and can be considered the first functional programming language, although it wasn’t directly based on the λ-calculus. (Even though there was a lambda keyword, it didn’t follow the rules of the calculus strictly.) A few years later, in the early 1960s, Landin used the λ-calculus in the design of Algol-60.
Today, lots of functional programming languages are built on top of the groundwork provided by the λ-calculus and its derivatives that mix in type theory. The interested, math-savvy reader is strongly encouraged to have a peek at those theoretical foundations: They can only make you a better programmer. Luckily, very little of this theory is required for C# developers to take advantage of lambda expressions, which you’ll see as we cover them in more detail.
This evolution illustrates the continuous knowledge transfer between the domain of pure mathematics and computer science. It’s a very healthy attitude for language designers to make sure the things they’re doing have a strong mathematical foundation. If the mathematicians haven’t figured it out yet, chances are slim that solid language features are built from loose ideas. Pretentious as it may sound, “mathematicians are always right” ought to be an axiom for programming language designers.
But why should we care about functional programming? I can come up with many good reasons, but the most prominent one nowadays is the challenge we’re facing in the world of multicore processors. It turns out functional programming is one promising avenue toward effective use of multicore processors, thanks to their side-effect-free nature. The pure functional programming language Haskell uses so-called monads (yet another mathematical concept, this time from the world of category theory) to track side effects in types. It turns out C#’s LINQ feature is deeply related to monads, as we discuss later when we talk about LINQ in more depth in Chapter 19, “Language Integrated Query Essentials.”
One use of lambda expressions is in LINQ queries where they’re invisibly present. For example, the use of the where clause specifies a filtering condition for the records being queried. Such filters, also known as predicates, can be expressed as little functions that take in a record and produce a Boolean value indicating whether the record should be included in the result set.
To illustrate this briefly, the following two queries are equivalent, where the first one is written using built-in syntactical sugar and the latter one has “compiled away” all built-in language constructs:
var res1 = from product in db.Products
where product.Price > 100
select product;
var res2 = db.Products
.Where(product => product.Price > 100);
Notice the appearance of a lambda expression in this metamorphosis. We cover this translation in much more detail when talking about LINQ.
Expression Trees
One of the more exotic language features in C# 3.0 are expression trees, which are closely related to lambda expressions. In the previous section, you saw how lambda expressions are used-potentially invisibly-in LINQ queries to represent little bits and pieces of a query, such as a filter’s predicate function or a projection’s mapping function. For local query execution, it makes perfect sense to compile those lambda expressions to pieces of IL code that can run on the local machine. But when the query is supposed to run remotely, say on a relational database engine, it needs to be translated into a target query language, say SQL.
LINQ providers that target external data stores therefore need a way to cross-compile the user’s intended query expression-that was written using LINQ-into whatever query language they’re targeting, such as SQL, XPath, and so on. Various approaches can be taken to solve this:
- Do not support extensibility for LINQ; instead, bake knowledge of various query languages into the C# compiler and let it do the translation. Clearly this is unacceptable from a maintenance point of view and clashes with the main goal of LINQ (that is, to provide unification of all sorts of query languages, including the ones we don’t know of yet).
- Have LINQ providers decompile the intermediate language (IL) code that was emitted by the C# compiler and go from there to the target query language. Not only would this be far too complicated to be widely accepted by query provider writers, but it also would prevent the compiler from changing its IL emission (for example, to add more optimization, given that query providers would expect specific patterns).
- Instead of turning lambda expressions directly into IL code, translate them into some kind of intermediate representation with an object model that can be consumed by query providers. This sounds much more promising, and this is where expression trees come in.
- So what are those expression trees? In essence, they are a way to represent code as data that can be inspected at runtime. Consider the following lambda expression:
(int a, int b) => a + b;
Two possible translations exist. The first one is to turn it into IL code that’s readily available for local execution, using delegates:
Func<int, int, int> add = (a, b) => a + b;
int three = add(1, 2);
The alternative is to assign the lambda expression to an expression tree, in which case the compiler emits the code as data:
Expression<Func<int, int, int>> add = (a, b) => a + b;
// the code represented by add can be inspected at runtime
A graphical representation of the expression tree used in our previous example is shown in Figure 2.3.
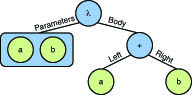
Note
To be absolutely precise, the compiler turns an expression tree into code that builds up a data structure representing the original code at runtime. This might sound mind-boggling, but it’s not that hard. Our sample code for the add function is turned into the following:
var a = Expression.Parameter(typeof(int), “a”);
var b = Expression.Parameter(typeof(int), “b”);
var add = Expression.Lambda<Func<int, int, int>>(
Expression.Add(a, b),
a, b);
When executed, this code calls into several factory methods that build up a data structure that represents (a, b) => a + b as data. For example, on the resulting add variable, one could ask for its Body property, which would return a binary expression object that represents the addition operation with operands a and b. Such knowledge can be used by libraries like LINQ to SQL to turn the code the user wrote into efficient SQL queries.
Luckily, as a user of LINQ, you don’t need to know anything about all of this, but it certainly doesn’t hurt to know how things work behind the scenes.
About quotations, meta-programming, and homo-iconicity
The concept of “code as data” is baked into the architecture of today’s computers, which are based on the von Neumann machine. In such a machine, the memory storage for instructions and data is the same, hence the ability to treat code as data. The reverse is also true, treating data as if it were code, which is the most prominent source of security bugs (for example, buffer overruns and execution of malicious script that was downloaded with an HTML page).
However, the notion of “code as data” is far too useful to let it go. Unsurprisingly, language features exploiting this rich capability have been around since the very beginning. LISP, a language for LISt Processing created in 1958, has a mechanism called quotations to suppress direct evaluation of expressions. Two LISP expressions are shown here, both adding two numbers but the latter being quoted:
(+ a b)
‘(+ a b)
It’s not hard to figure out where the name “quotations” comes from, is it? LINQ expression trees actually have an expression node type named after this (constructed through the Expression.Quote factory method), and the F# language has built-in support for a similar mechanism of quoting pieces of code:
let add (a:int) (b:int) = a + b
let quotedAdd (a:int) (b:int) = <@ a + b @>
All of those quotations are similar in nature to the C# 3.0 expression:
Expression<Func<int, int, int>> add = (a, b) => a + b;
The ability to represent code as data is the cornerstone to enabling meta-programming facilities in the platform and the language. Meta-programming is the capability of code to inspect and manipulate code at runtime, which is a very rich concept. It might sound rather abstract at first, but it’s real and in use today. Tools such as Reflector are one example of inspection of code. Frameworks such as the LINQ provider model illustrate the richness of runtime code inspection, too. Refactoring tools are a form of code manipulators.
Expression trees in C# 3.0 (and VB 9.0) form the tip of the iceberg of the envisioned meta-programming capabilities on the .NET platform. With the release of .NET 4.0 and the dynamic language runtime, those expression trees have grown out to full-fledged statement and declaration trees that can represent whole programs.
Finally, some trivia for true geeks. The capability to represent code written in a language by other code in that language makes that language deserve the status of being homo-iconic: homo = same, iconic = representation. Since version 3.0, C# has been homo-iconic for the expression subset of the language, thanks to the introduction of expression trees.
As you can see, expression trees are a very powerful concept to inspect code at runtime and have a reach that goes much beyond their use in LINQ. One can think of them as “reflection on steroids,” and their importance will only increase in the releases to come.
Auto-Implemented Properties
One feature outside the direct realm of LINQ made it into the C# 3.0 release: automatically implemented properties. With this feature, adding trivial properties to a type definition becomes much prettier than it used to be.
What’s a “trivial property,” anyway? Properties are sometimes called smart fields, so one of the most common patterns is to wrap field accesses in a property, and that’s it:
private int _age;
public int Age
{
get { return _age; }
set { _age = value; }
}
You’ll agree that exposing the field directly wouldn’t be a good idea because of the lack of encapsulation, a crucial technique in object-oriented programming. But why should we even have to bother defining an internal backing field if all we do with it is expose it through a property directly?
That’s where auto-implemented properties come in. In C# 3.0, you simply get to write the following instead:
public int Age
{
get; set;
}
The compiler synthesizes a private hidden backing field for you, and life is good. Both a getter and a setter are required, but they support having different visibilities (for example, to create more or less immutable data structures):
class Person
{
public Person(string name)
{
Name = name;
}
public string Name
{
get; private set;
}
}
If you ever want to turn the property into a nontrivial one, you can still go back to the classic syntax and manually implement a getter/setter accessor without breaking the property’s consumers.
Note
Some people refer to this feature as “automatic properties.” I don’t like that because the word automatic seems to make people attribute magical runtime powers to those properties (“Hey, it’s automatic...ought to be better”), even though they’re nothing but a compile-time aid to reduce the amount of code a developer has to type. That alone makes them a bit magic, but solely at compile time. This said, I can understand why people want to abbreviate language feature names in spoken language; after all, terms such as auto-implemented properties can be quite heavy on the tongue.
C# 4.0: Reaching Out to Dynamic Languages
The introduction of LINQ was a theme that drove the language evolution for both C# and Visual Basic in the .NET Framework 3.5 timeframe. This kind of scenario-driven language design formed a milestone in the history of the language and has been received very well by developers. Following this philosophy, C# 4.0 also focuses on making a key scenario that causes grief for developers much easier to deal with. Where C# 3.0 made data access easier, the fourth release of the language aims at making code access much simpler than it used to be.
A Perspective on Dynamic Languages
The capability to bridge the gap between different languages has always been a core design theme of the .NET platform, leading to its unified type system and code-execution infrastructure. However, before the advent of the DLR, there was a dark spot in the language integration gamma: dynamic languages. Despite the goal to simplify cross-language integration, little attention was paid to the domain of dynamic languages. This isn’t too surprising, considering their popularity was relatively low at the time the CLI was designed, therefore making statically typed languages a much more attractive target for the platform.
Around 2005, half a decade later, the resurgence of dynamic languages was accepted as fact. Technologies like JavaScript gained attention because of AJAX web programming, interactive development experiences brought by languages like Python grew in popularity, and the meta-programming facilities of platforms like Ruby on Rails made it an attractive target for web programming. Dynamic was back, potentially stronger than ever.
The story of a guy called Jim... or how the dynamic language
runtime was born.
Not everyone believed that CLR would be a good fit as the underlying runtime to enable execution of dynamic languages. One such guy was Jim Huginin, who created Jython, an implementation of the Python language on the Java Virtual Machine (JVM).
But why was this perception of the CLI being an unfriendly environment for dynamic languages hanging around? Remember Project 7, the initiative run at the time of the CLI’s inception to port a set of popular languages to the CLI as a sanity check for the multilanguage design of the platform. Back then, an attempt, led by ActiveState, was made to implement Python on .NET, concluding the performance of the CLI to be inadequate for dynamic language execution.
Jim wanted to figure out what made the CLR a hostile environment for dynamic languages and decided to have a go with a .NET-based Python implementation. His plan was to share his findings in a paper titled, “Why .NET Is a Terrible Platform for Dynamic Languages.” In a matter of a couple of weeks, Jim had a prototype ready and came to realize it actually ran much faster than Jython. Jim became a convert to the CLR and joined Microsoft in August 2004 to become the architect of the Dynamic Language Runtime, with IronPython as the first language on top of it.
At a later stage, IronRuby was added to the family of dynamic languages targeting the DLR, and implementations of the DLR and both languages were shared with the .NET community through Microsoft’s shared-source site CodePlex. Since the release of .NET 4.0, the DLR has become an integral part of the framework.
What Makes a Language Dynamic?
Often abbreviated as dynamic languages, we really mean to say dynamically typed languages. So the core difference between those languages and their static counterparts is in the typing. Let’s explore this a little bit more to set the scene.
In a statically typed language, the compiler knows the types of all the variables, fields, and method parameters that occur in a program. Therefore, it can carry out compile-time checking to make sure operations invoked on these objects are valid based on the type information available. For example, in the following piece of code, the compiler knows that the type of variable s is System.String (because we’ve declared it as such), and from that it can prove that ToUpper is a valid method call because System.String has it:
string s = “Some text”;
string u = s.ToUpper();
Do not confuse local variable type inference-the var keyword introduced in C# 3.0-with dynamic typing. This feature still provides full strong and static typing; it just enables us to let the compiler figure out the type on our behalf. Nevertheless, if we attempt to carry out a nonexistent operation on an implicitly typed local variable, the compiler will still detect the problem. In other words, type checking still happens at compile time.
For example, the two declarations in the following code mean exactly the same (both variables have type System.String, which was inferred for the latter one):
string s1 = “Some text”;
var s2 = “More text”;
However, typing any of those variables as dynamic has a fundamentally different meaning, causing runtime lookups to happen for every operation invoked on it.
On the other hand, in a dynamically typed language, we don’t need to specify any types upfront. Typically, there’s no need for the developer to compile the code (often referred to as “script” in the context of dynamic languages); instead, it gets executed immediately through interpretation or by compiling the code at runtime. This allows for a very interactive experience where code can be typed and executed immediately in an interactive prompt, just like command shells. The following is an example of dynamically typed code:
s = “Some text”
u = s.ToUpper()
Only at runtime can the system determine whether ToUpper is a valid operation to be carried out on variable s because type information becomes available only at that point. If s would happen to be an integer value instead, the call to ToUpper would fail no earlier than at runtime.
Word of the day: REPL
Interactive prompts for programming languages are called REPLs, which stands for read-eval-print-loop: Code is read from the console, evaluated by some runtime service, and the result is printed out. This interactive process keeps going until the developer quits, making it a loop.
However, lots of people believe REPLs are a luxury exclusively available to the dynamic language programmer. Nothing is further from the truth, though. Nowadays, statically typed languages like F#-and potentially C# in a future release-offer interactive prompts while preserving full static typing. It’s just that those environments typically do a great deal of type inference to reduce the amount of types the user has to specify explicitly.
The “Static Versus Dynamic” War
Dynamic languages have caused quite some controversy over the years, especially in circles of believers in statically typed languages. The advantages of static languages are numerous:
- Robustness is perhaps the most cited benefit of static typing. The capability to catch problems early by means of static type checking enables you to uncover issues early. Or in other words, if it compiles successfully, it runs.
- Performance is another big advantage attributed to static typing. Because no runtime support is required to resolve members on types, the compiler can emit efficient code that doesn’t beat about the bush.
- Rich tooling support can be realized by leveraging the type information that’s statically available at development time. Popular power toys like refactoring engines and IntelliSense are just a couple of examples of this.
- Scalability should be called out, too. The capability to make types a means for defining strong contracts between different components has the potential of reducing the maintenance cost of complex systems as the system grows.
Nevertheless, it’s wrong for statically typed languages believers to curse all the dynamic world as if it were inferior. In times when the Internet is glued together by script execution, loosely typed XML files are flying around, and large frameworks-such as Ruby on Rails-have been written based on dynamic languages, we can’t close our eyes and ignore dynamic typing.
The truth is there are increasing numbers of things that are weakly typed: XML without an XSD schema, REST services, Python and Ruby libraries, even old COM APIs, and so on. Before the advent of the DLR and .NET 4.0, the dynamic landscape was rather worrisome for developers. Static language compilers refuse to emit code that’s loosely typed, and therefore people have been looking for different ways to overcome this limitation through APIs. Unfortunately, there’s no general approach to writing dynamic code. Each dynamic “domain” has its own APIs without any unification or consolidation between the domains whatsoever.
For example, suppose you get a .NET object from somewhere whose static type you don’t know, but you happen to know the object has an Add method on it. To call it, you can’t simply write the following:
object calculator = GetCalculatorFromSomewhere();
int three = calculator.Add(1, 2);
Instead, you have to go through the hoops of .NET reflection to call the method, like this:
object calculator = GetCalculatorFromSomewhere();
int three = (int)calculator.GetType().InvokeMember(“Add”,
BindingFlags.InvokeMethod, null, new object[] { 1, 2 });
It almost takes a Ph.D. to come up with this kind of code, and you get lots of new worries in return: unreadable and hard-to-maintain code, potential optimization headaches, and so on.
But matters only get worse as you enter different domains. Instead of being able to reuse your knowledge about dynamic invocation techniques, you must learn new APIs. For example, the following code tries to reach out to a JavaScript calculator object through the Silverlight APIs:
ScriptObject calculator = GetCalculatorFromSomewhere();
int three = (int)calculator.Invoke(“Add”, 1, 2);
Similar in spirit but different in shape. This is just the tip of the iceberg; lots of other domains face similar problems, even though developers hardly think about it anymore. What about the XML you got from somewhere, without an XSD schema going with it? In times of REST-based web services, such an approach is becoming more and more popular, but consuming such an XML source gets quite painful:
XElement root = GetCustomerFromSomewhere();
int zip = int.Parse(root.Element(“Address”).Attribute(“ZIP”).Value);
This mess puts language designers at an interesting juncture: Either follow the direction of static language purity or take a turn toward a “better together” vision. Either you can make it incredibly hard for developers in static languages to reach out to dynamically typed pieces of code or data (as shown earlier), or you can open up for a smooth road to call into the dynamic world.
C# 4.0 dynamic does precisely that: makes it easy for developers to ease into various domains of dynamically typed code and data. Just like LINQ unified data access, you could see the dynamic feature unifies dynamic access. For example, the Calculator example targeting either .NET objects or JavaScript objects could be written as follows:
dynamic calculator = GetCalculatorFromSomewhere();
int three = calculator.Add(1, 2);
Pragmatism versus purity
The fact that C# 4.0 embraces dynamic typing to solve real-world problems developers face emphasizes one of the core properties of the language: its pragmatic nature. This is what makes C# such a popular language in the .NET community: its sense for real problems by providing elegant solutions. LINQ is another example of this. Some may say this affects the purity of the language, but the reality is there aren’t that many pure successful languages out there. At the end of the day, software developers scream for practical languages as opposed to the scientifically pure but impractical ones.
The dynamic Keyword
The only language surface for the dynamic feature is a correspondingly named keyword, as shown in the previous example. Variables, members, or parameters that are typed as dynamic will have late-bound behavior. This means whenever an operation, such as a method call or property access, is invoked on the object, its resolution gets deferred until runtime.
Let’s contrast early-bound code to late-bound code. The first example is early-bound code:
Calculator calculator = GetCalculatorFromSomewhere();
int three = calculator.Add(1, 2);
Here the compiler knows precisely what the type of the calculator variable is: It’s statically typed to be Calculator, so operations on it can be checked during compilation. When the compiler encounters the Add method call on the next line, it tries to find an overload that’s compatible with taking in two integer values and returning an integer value. If it finds a suitable candidate, it emits IL code to call that method immediately at runtime. If no good overload is found, a compile-time error results.
In the dynamically typed code, the call to Add is resolved at runtime:
dynamic calculator = GetCalculatorFromSomewhere();
int three = calculator.Add(1, 2);
Now the compiler doesn’t even bother to find an Add method at compile time because it simply doesn’t know what the type of the calculator variable will be. Instead of emitting IL code to call directly into a known early-bound method, it emits code to invoke the overload resolution logic at runtime. If a good match is found, the DLR will step in to provide efficient call site code generation so that subsequent calls do not suffer from overload resolution again. If overload resolution fails, a runtime exception results.
dynamic != var
Do not confuse the dynamic keyword with the var keyword from C# 3.0. The var keyword is as statically typed as it possibly can; it just enables you to omit the type and let the compiler infer it for you:
var languages = new List<ProgrammingLanguage>();
The preceding line means exactly the same as the much more verbose variant:
List<ProgrammingLanguage> languages = new List<ProgrammingLanguage>();
Trying to call a nonexistent method on the languages variable, say the misspelled Addd method, will result in a compile-time error. Or even better, the Visual Studio editor will catch the error immediately because all static type information is readily available.
In contrast, with the dynamic keyword, you’re essentially telling the compiler not to bother attempting to infer the type, having it do overload resolution at runtime instead.
A more detailed explanation about how the C# compiler emits code that causes the DLR to kick in-allowing it to reach out to any kind of dynamically typed code-will follow in Chapter 22, “Dynamic Programming.”
Static when possible, dynamic when necessary
The introduction of dynamic doesn’t mean you should start rewriting all your statically typed code to use dynamically typed code instead. Static typing has many advantages, and C# stays faithful to that belief. So whenever possible, use static typing-it’s pure goodness.
But other than before the introduction of C# 4.0, when you absolutely need to go for dynamic typing, it’s no longer a mission impossible to get it to work while keeping the code readable and maintainable. What the new dynamic feature really enables is to “gradually ease into” dynamic domains without sacrificing developer productivity.
By the way, if you don’t like dynamic at all and you want to keep people from using the feature, I have good news. It’s relatively straightforward to disable dynamic support simply by emitting the “C# binder” during compilation (which can be achieved through the Visual Studio 2010 IDE, for instance). I’ll get back to that later when we cover dynamic end to end.
What the DLR Has to Offer
Execution of dynamically typed code relies on quite a few runtime services, such as overload resolution, code generation, and caching of acquired runtime data, to improve efficiency of calls. Let’s explore what’s involved in making a dynamic call.
First, the language compiler generates code to package up all the information it has about the intended call. This includes the type and name of the operation being invoked-for example, a property called Price, a method called Add, and so on-as well as information about the arguments passed in to it. To turn this information into usable information at runtime, the compiler emits code that targets helper libraries, collectively called the C# binder. Other languages targeting dynamic code have similar binders.
Next, during execution, the runtime type of the target and arguments of the call become available. Now it’s up to the target domain-for example, Python, Ruby, JavaScript, regular .NET objects, COM APIs, you name it-to decide whether that call makes sense. This is the part that is involved with overload resolution and such, allowing the target domain to enforce its semantics. Each such domain has a runtime binder to carry out those tasks.
If a suitable operation target is found, the runtime binder emits expression trees that contain the code required to carry out the call. From this point on, all that keeps us from executing the code is a runtime translation of the expression trees into code that can run on the underlying execution engine, the CLR.
This last part, where expression trees get turned into real code, is the crux of the DLR. Among code generation, it also offers APIs for the expression trees it accepts, as well as runtime services to cache generated pieces of codes and provide fast paths to a call target, bypassing all runtime binder interactions after initial calls have been made. So where the CLR provided common infrastructure for statically typed languages, the DLR acts as a library on top of it, ameliorating it with support for dynamically typed languages.
Note
The expression trees used by the DLR are the natural evolution of LINQ’s expression trees that were introduced in the .NET 3.5 timeframe. In the world of querying, the only required “code as data” formats required are expressions: roughly, things that evaluate to have a value (for example, predicates or projections):
person.Age > 25
Expressions are insufficient to represent complete meaningful programs. To do that, we need statements that include control flow constructs such as loops and conditions:
if (person.Age > 25)
Console.WriteLine(“Hello, “ + person.Name);
The DLR needs to be able to deal with the latter format for sure because it provides a unified execution back end for dynamic languages like Ruby and Python that hand over the user’s code in a tree format. Trees with the capability to express statements are called (how original) statement trees.
There’s yet another level above statement trees: declaration trees. With these, it also becomes possible to represent entire type and member definitions in a tree format that can be consumed by the runtime and tools to generate IL code.
Confusingly, the collective set of trees is often referred to as expression trees, even though they have more expressive power than the original LINQ expression trees. What makes expression trees-sensu lato-an interesting topic is their role as the cornerstone in enabling “compiler as a service.” To get to know what that is, read on.
The end-to-end picture of the DLR’s role in enabling this full mesh between lots of front-end languages and even more dynamic target domains is shown in Figure 2.4. Some of the binders mentioned here are available out-of-the-box, while others ship with separate downloads, such as the IronRuby distribution.
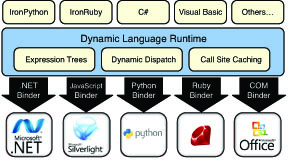
Starting with .NET 4.0, the DLR is available out of the box as part of the .NET Framework, for languages to be implemented on top of it and for others to bridge with the dynamic world.
Improving COM Interop
Despite the .NET platform’s classification as a successor to COM, there are still a huge number of COM-based APIs around that developers need to integrate with. Since the earliest version of the .NET Framework, COM interop facilities have been built in to the runtime and the libraries to make this possible, mainly with regard to mapping of types back and forth and to facilitate COM calls.
At the same time, the designers of C# thought it was inappropriate for the language to support a COM style of programming where it’s not uncommon to have methods that take a bunch of parameters, most of which are optional and/or passed by reference. Part of the whole .NET design mission was to make APIs more consistent and approachable, and COM wasn’t always a particularly good stylistic example.
This led to an unfortunate dichotomy where Visual Basic (and Managed C++) were much more attractive languages to deal with COM interop, leaving C# developers out in the cold. Although various COM APIs have been exposed through cleaner managed APIs, the capability to talk to the bare COM metal is still required often enough to warrant the design and implementation of improved COM interop in the C# language.
One classic example of COM-based APIs is the Office automation libraries, which can be accessed in managed code through primary interop assemblies (PIAs) that are available from Microsoft. Here is an example of interop code required to create an Excel chart using C# 3.0:
Excel.Worksheet wks = GetWorksheet();
// ...
wks.Shapes.Add(XlChartType.Bar, Type.Missing, Type.Missing, 400, 300);
Notice the use of Type.Missing to fill in the holes for optional parameters? With C# 4.0, it now becomes possible to specify parameters by name, like this:
Excel.Worksheet wks = GetWorksheet();
// ...
wks.Shapes.Add(XlChartType.Bar, Width: 400, Height: 300);
The capability of APIs to declare optional parameters by supplying a default value and for consumers to skip such parameters vastly improves common COM interop scenarios. We refer to this tandem of features as named and optional parameters.
Named parameter syntax
You might wonder why the colon (:) symbol is used to specify values for parameter by name, as opposed to the more natural-looking assignment (=) symbol. The reason, once more, is backward compatibility. Although it’s strongly discouraged to write code like this, it’s perfectly valid to do so in C#:
wks.Shapes.Add(XlChartType.Bar, Width = 400, Height = 300);
This piece of code assigns the value 400 to something with the name Width, using the resulting value from that assignment as the second parameter to the Add method call. This is similar for the third parameter, which gets its value from a side-effecting assignment operation, too. If this syntax were to be used for named parameters, existing code that relies on this would start breaking. Although people who write this sort of code should be punished, backward compatibility means a lot to the C# team, and hence the alternative syntax with the colon was chosen.
Another feature introduced in C# 4.0 is the capability to omit the ref modifier on parameters for COM interop method calls:
Word.Document doc = CreateNewDocument();
// ...
string fileName = “demo.docx”;
object missing = Type.Missing;
doc.SaveAs(ref fileName,
ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing,
ref missing, ref missing, ref missing);
No less than 15 optional parameters, all of which had to be supplied by reference! With C# 4.0, you get to write the code as it was always intended to look by the COM API:
Word.Document doc = CreateNewDocument();
// ...
doc.SaveAs(“demo.docx”);
This feature is known as the optional ref modifier.
Note
Optional ref modifiers are not a general language feature; this relaxation for parameter passing by reference applies only to COM interop scenarios, where this style is the default.
The need to specify the ref modifier explicitly in all other cases is pure goodness. It makes it very explicit for readers to see where arguments are passed by reference and where not:
int answer = 42;
Do(ref answer);
// The answer might not longer be 42 as it was passed by reference.
Being explicit about this prevents surprises, especially because passing arguments by reference is not the default in .NET. In COM, that’s different, causing lots of syntactical noise when trying to use such APIs in managed code. Therefore, it makes sense to relax the rules for those scenarios.
Although we’re in the domain of method calls, another feature worth mentioning is the automatic mapping for parameter and return types from object to dynamic. Lots of COM APIs deal with System.Object-typed parameters and return types to allow maximum flexibility. However, to deal with those from managed code, one typically wants to cast to some interface (corresponding to a QueryInterface COM call) provided for COM interop. This gets cumbersome pretty soon, requiring lots of boilerplate code, especially when dealing with return values. This kind of experience is often referred to as “peter-out typing” because along the way you lose strong typing:
Workbook workbook = GetWorkbook();
Worksheet sheet = (Worksheet)workbook.Sheets[“Products”];
Range range = (Range)sheet.Cells[1, 1];
// Use the selected range.
In the C# 3.0 code here, the return types for the indexers into the Sheets and Cells collections are statically typed to System.Object, so we need to cast to the appropriate interface to continue. The reality is that COM is a dynamic experience to begin with-the IDispatch interface being the ultimate example-so it makes sense to reduce this friction when dealing with COM interop. Therefore, starting from .NET 4.0, occurrences of System.Object in COM APIs are substituted by dynamic. This causes the DLR to kick in and use the COM binder to call into the underlying COM APIs:
Workbook workbook = GetWorkbook();
Range range = workbook.Sheets[“Products”].Cells[1, 1];
// Use the selected range.
A final language feature that falls under the umbrella of improving COM interop is known as “no PIA.” (Kind of weird for a language feature to have a negation in it, isn’t it?) Historically, Microsoft has shipped so-called PIAs for popular COM libraries, containing the exported type definitions with several enhancements to make the APIs easier to consume from managed code. Although great, PIAs are typically hogs in terms of size, and in the majority of cases only very small parts of the library are used. This causes grief with regard to the size of applications-relevant for deployment-and because of the runtime cost associated with loading giant assemblies.
With “no PIA,” the compiler can grab all the bits and pieces of a PIA that are used within the application’s code and copy them into the application assembly being built. This eliminates the need to redistribute PIAs and reduces the load cost to a minimum.
Language co-evolution
Since the introduction of .NET, Microsoft has offered two mainstream managed code languages: C# and Visual Basic. Although this perfectly illustrates how the platform enables a wide variety of languages to be used for managed code development, it’s been a major source of confusion for developers who have to make a language choice. Both languages more or less target the same group of developers, writing enterprise applications of various kinds.
Ideally, the main reason to prefer one language over another should simply be a matter of background and personal preference. People coming from a C++ or Java background will feel more at home in C#, whereas those who had prior exposure to Visual Basic 6 or earlier will find Visual Basic .NET more attractive.
In reality, differences in the gamma of language features offered by both languages have been a source of frustration, forcing people to choose a particular language or be left in the dark with missing features. Over the years, it became apparent this pathological situation should be dealt with, and starting from .NET 4.0, Microsoft has committed to “co-evolution” for both languages, making sure they keep on par with regard to features being added.
One can see traces of this commitment in both languages today. C# 4.0 is adding named and optional parameters, something Visual Basic has had from the start. In the opposite direction, Visual Basic 10 now supports auto-implemented properties that were in C# since version 3.0.
Covariance and Contravariance
Without a doubt, the most fancy-sounding new feature in C# 4.0 is generic interface and delegate type co- and contra-variance. I won’t dive into details on the technical terminology used here, so let’s just focus on what it enables instead.
A common situation people ran into when using LINQ was the following:
IEnumerable<Person> result = from student in db.Students
where student.Name.StartsWith(“B”)
select student;
In this piece of code, the type of the elements in the Students table is Student, which is a subtype of Person. However, to treat the resulting sequence-an IEnumerable<Student>-in a more general fashion, we’d like to assign it to a variable of type IEnumerable<Person> instead. In C# 3.0, people were surprised you couldn’t do this, although it seems safe on the surface.
The reason this didn’t work is because generic types were treated invariantly by the language before the introduction of C# 4.0. This means generic parameters had to match exactly for the assignment to work. However, IEnumerable<T> is safe to be used covariantly, which means an object of type IEnumerable<SubType> can be used where an IEnumerable<SuperType> is expected. Why is this safe to do? I’ll omit all the gory details, but the essential point is that the generic parameter is only used in “output positions” in the interface definition:
interface IEnumerable<T>
{
IEnumerator<T> GetEnumerator();
}
Because it’s only possible to get values of type T out of the interface (through the enumerator object, that is), it’s safe to treat them as less derived: “Okay, we got Student objects back, but ignore the things that make a Student special and treat them as regular Person objects instead.” However, if we’d be able to feed objects in through the interface, this wouldn’t be safe anymore (for example, because you’d be able to stick a Docent object into the collection while consumers expect objects to be of type Student). This would breach type safety.
A similar issue exists when generic parameters are used in input positions (for example, on the IComparer interface shown here). In C# 2.0 and 3.0, the following wouldn’t compile:
IComparer<Person> personComp = GetPersonComparerByWeight();
IComparer<Student> strComp = personComp;
Intuitively, you can see this should be fine: if something can compare arbitrary Person objects, it ought to be able to compare Students, too, because every Student is a Person, at least in our type hierarchy. This case is exactly the opposite as the IEnumerable<T> case: Now we can treat something less derived (an IComparer for Person objects) as more derived (comparing Students). We call this contravariance. Again, with C# 4.0 you’re now able to do this.
Given that contravariance is the opposite of covariance, can you guess why this is safe for IComparer<T>? Because this time T is used in “input positions” only, as illustrated here:
interface IComparer<T>
{
int CompareTo(T left, T right);
}
Typically, all you need to know about this theoretically very interesting feature is that now you can do the things you were surprised you couldn’t do before. This reflects the use of covariance and contravariance. The feature is symmetrical, though, allowing developers to declare generic interface or delegate types with variance annotations on type parameters. How this has been done for the BCL types IEnumerable<T> and IComparer<T> is shown here:
interface IEnumerable<out T>
{
IEnumerator<T> GetEnumerator();
}
interface IComparer<in T>
{
int CompareTo(T left, T right);
}
Here the in and out keywords are used to indicate the variance treatment for the parameter. Covariance is specified using the out keyword, restricting the type parameter’s use to output positions only. Likewise, contravariance is indicated using in, this time allowing the parameter to be used in input positions only. The compiler will enforce this to make sure you don’t put type safety at risk.
Note
Covariance and contravariance are not limited to the context of generic types. In fact, since C# 3.0, the language has support for both types of variance for (nongeneric) delegate types. This proves particularly handy when dealing with event handlers. Suppose, for example, we want to have one handler both for a MouseClick event on a button and a KeyPress event on a text box. These events are defined as follows:
public event MouseEventHandler MouseClick;
public event KeyPressEventHandler KeyPress;
The delegates used to define the events look like this:
delegate void MouseEventHandler(object sender, MouseEventArgs e);
delegate void KeyPressEventHandler(object sender, KeyPressEventArgs e);
While having specialized knowledge about the events that occurred through their arguments (for example, the mouse cursor position at the time of the click), we might just be interested in the mere fact that any of those events happened without requiring additional context. In other words, we want to write the following:
txtAmount.KeyPress += this.LoggingHandler;
btnSave.MouseClick += this.LoggingHandler;
In this case, the event handler method is declared like this:
private void LoggingHandler(object sender, EventArgs e)
{
// ...
}
See what we just did? We used the common super-type System.EventArgs on our general-purpose logging handler. Thanks to C#’s delegate covariance and contravariance feature, this is allowed, providing more flexibility when matching method signatures against delegate types. Parameter types are treated contravariantly, while return types are treated covariantly.
A Sneak Peek at the Future
Now that we’ve seen the current state of affairs of the C# language, let’s talk a bit about the influences that are shaping the language’s future.
Multiparadigm
Traditionally, programming languages have been classified based on the paradigms on which they’re based:
- Imperative programming languages use statements to modify the state of a program. Those languages are very machine-oriented and reflect how the underlying hardware works, hence giving developers low-level control over the system. Writing software following this paradigm is about stating “how” execution needs to happen, not just about “what” the problem is that needs to be solved. The earliest imperative programming language was FORTRAN, and popular descendants include COBOL, BASIC, Pascal, and C.
- Procedural programming extends on the foundation laid by imperative languages, adding more structure to the way software is written by adding the concept of procedures. Declared once, procedures can be called many times to reuse pieces of code. This also helps to isolate state used across multiple procedures, making the program as a whole more modular. It also gets rid of excess use of GOTO to control the flow of execution.
- Object-oriented (OO) programming is today’s most popular paradigm to tame complexity of software. Code is divided into object definitions (types) that define state and operations on that state. By keeping the internal state of an object hidden from the outside world (known as encapsulation), better modularity arises. Other techniques in the OO paradigm include polymorphism and inheritance. Languages such as Smalltalk, Eiffel, C++, Java, C#, and Visual Basic .NET can be classified as object-oriented.
- Declarative languages shy away from modification of machine state and take a top-down approach, starting from the problem definition (what) and hiding the execution details (how) such as control flow from the developer. This style reduces the number of side effects and is regaining attention lately because of concurrent programming.
- Functional programming is a subcategory of declarative programming. As the name implies, it’s based on the concept of mathematical functions, avoiding mutation of state and side effects whenever possible. This makes reasoning about the program’s behavior easier and has the tendency to eliminate whole classes of bugs. It also allows parallelization of execution with fewer worries than in the imperative world. Sample languages include LISP and Schema, the ML-family of languages, and its derivatives like F#, Haskell, and Erlang; but even spreadsheets can be considered functional.
- Logic programming is more of a niche market but is another great example of declarative programming. This paradigm tends to be popular in the development of rule engines. The idea here is that the developer expresses logical rules, after which logical questions can be asked to the program, having it figure out how to prove or disprove the correctness of the question. Probably the most notable logic programming language is Prolog.
Yet another taxonomy is established along the axis of typing, with a distinction between statically and dynamically typed languages.
Over the years, C# has become more and more of a multiparadigm language, with bits and pieces from various domains. “Pure” languages do not seem to have the reach they once had for filling in the needs for general-purpose programming tasks.
At its core, C# is an object-oriented programming language, and .NET’s BCL is based on the principles of OO. Since the introduction of C# 3.0, one can argue that C# has become a functional programming language, too, with first-class functions and concise notation using lambda expressions. This happened “by accident” somewhat as a side effect of introducing LINQ, which is based on the lessons learned from the functional programming world.
Note
Categorizing C# as a functional programming language is acceptable in the broad sense of the term: the capability to program with functions. However, true functional programming makes every use of side effects explicit through so-called monads. The form of functional programming can be seen as extremist pure functional programming. Haskell is the best example of a language that falls under this category.
The truth is we need side effects to do useful stuff. If everything were a pure mathematical function, we could substitute our whole program by a simple constant. Even simple tasks such as input/output (for example, from/to the screen) should be considered side effects. Requiring the developer to be explicit, in terms of types, about side effects everywhere they occur doesn’t fit very well in a framework that’s centered on the OO paradigm where mutation is a core feature.
With the introduction of C# 4.0, one can say C# has also become a dynamic language, though; the use of dynamic dispatch is made very explicit through the use of the new dynamic keyword.
Moving forward, you can expect more paradigms to be added to the mix. Some people argue this spoils the “purity” of the language, but in today’s melting pot of cross-language interoperability-greatly stimulated by Internet programming-to be relevant, languages need to have the means to reach out to other worlds easily. This is a common theme for many languages today: Dynamic languages are adding islands of static typing, functional concepts are observed everywhere (including C++0x, the latest C++ standardization proposal), and so on
Language-Shaping Forces
To understand what to expect from the future evolution of mainstream programming languages like C#, we should first take a look at the themes that are gaining popularity and at the challenges ahead:
- Meta-programming facilities are popping up in various platforms today. Nearly every enterprise application written today contains code that has been generated somehow (for example, to wire up user interface controls, to carry out mappings like object-relational [O/R], or to consume web services through generated proxy objects). This trend is definitely calling for a more accessible object model to represent code.
- Concurrency was once a niche market given the low number of machines that could execute code in parallel. Today it’s nearly impossible to purchase a new computer with just one processor core in it. Because general-purpose programming languages evolve, they’ll need to provide means to structure and write code that allows for better parallelization. There are still lots of open questions in this space, with no silver bullet.
- Declarative programming is about yielding more control to the runtime when it comes to executing code. Today, developers tend to overspecify the solution to the programming task at hand. Our programs are embarrassingly imperative, leaving the runtime no choice but to execute the program exactly as it has been written, with little room for the runtime to be smart about how to execute the program.
- Domain-specific languages (DSLs) bring islands of domain specialization to the programmer toolbox. When developing software, the original problem domain often gets lost in the translation into concepts of language targeted by the programmer. Over the years, we’ve seen an ever-increasing number of little specialized languages being built for various domains (for example, querying). Allowing integration with general-purpose languages might be next.
The next sections sketch a couple of ideas the language teams at Microsoft are playing with as we speak. When and how those technologies will be shipped is something left open for the time being.
Compiler as a Service
As I’m writing this chapter, the managed language teams at Microsoft are working full speed to turn the C# and Visual Basic compilers into managed code for a subsequent release of the framework. This work will open the road to lots of scenarios in the field of meta-programming.
Today, Microsoft’s C# and Visual Basic language compilers are black boxes: Source code goes in, and assemblies come out, but what goes on in the middle is shielded away from the users. With C# 3.0, the need to expose parts of the code representation-expression trees more specifically-became apparent as a cornerstone to allow the creation of LINQ providers. In such a setting, LINQ providers play the role of runtime extensions of the compiler, inspecting code as data and turning it to execution (for example, by generating SQL statements).
This trend of opening up the code representation has continued with the advent of the DLR, but moving forward it’s desirable to have an object model for code that can be shared by various languages, including old giants like C# and Visual Basic. The port of the compilers’ code bases to managed code is the first step in that direction.
Note
One can think of the code-as-data mantra as an extension to the reflection capabilities that have been present right from the start of .NET. The use of reflection allows code to inspect types and their structure at runtime and forms the cornerstone of dynamic code execution.
With .NET Framework 1.x, reflection was a one-way street: only loaded assemblies and their types could be inspected, but it wasn’t possible to build new types on the fly. In the second release of the framework, this changed a bit with the introduction of Lightweight Code Generation (LCG). Using LCG, code can be emitted at runtime but at a high developer cost: having to deal with IL instructions, which can be an error-prone business.
Other avenues to code generation have been explored in the past. One such technology is the Code Document Object Model (CodeDOM), which enables developers to generate source code at runtime, resulting in a source code graph that can then be consumed by CodeDOM providers to compile the code into an assembly. Providers exist for Visual Basic, C#, JScript, and F#. Although this model works for whole-type code generation, it’s too coarse-grained and heavyweight for generation of small pieces of code (for example, to represent a single method with no containing type). A typical use of CodeDOM is for code generation tools, like O/R mappers.
With the development of the new generation of compilers, a unified code object model arises that can be used for various scenarios ranging from tool-driven code generation to lightweight code generation at runtime.
This whole idea is often referred to as compiler as a service (CaaS) because the managed code compilers will become available as runtime libraries that are easy to deal with. With this infrastructure in place, the meta-programming sky becomes the limit:
- Code manipulation and inspection tools like refactoring engines or code verifiers like FxCop become available for anyone to write and extend.
- Read-Eval-Print-Loops (REPLs) come into reach for (mostly) statically typed languages like C#, allowing for an interactive development experience.
- Model-driven software benefits from the capability to translate a model definition into executable code at runtime.
- DSLs can now host islands of general-purpose code. (For example, an MSBuild file could contain C# code fragments.)
- Compile-time participation becomes a possibility, allowing compile-time code rewriting for purposes such as optimization or instrumentation.
When exactly all of this will happen is yet unknown, but the potential is too big to be ignored.
Taming the Concurrency Beast
Every software developer should have heard about Moore’s law:
The complexity for minimum component costs has increased at a rate of roughly a factor of two per year. Certainly over the short term this rate can be expected to continue, if not to increase. Over the longer term, the rate of increase is a bit more uncertain, although there is no reason to believe it will not remain nearly constant for at least 10 years. That means by 1975, the number of components per integrated circuit for minimum cost will be 65,000. I believe that such a large circuit can be built on a single wafer.
Gordon Moore, Electronics, Volume 38 (April 1965)

All the way back in 1965, Gordon Moore (cofounder of Intel) formulated his empirical law, predicting a doubling of the number of electronic components on a chip roughly once a year. In practice, this meant a steady exponential speed-up for processors, an ideal excuse for software developers to stick their heads in the sand when it comes to performance optimization: “Wait a few years, and what’s slow today will be fast enough.”
Although this law still holds, giving us more transistor density on chips, it no longer comes with a proportional speed-up (due to heat-dissipation issues and such). So instead of giving us higher clock speeds, processor vendors are now giving us more cores per chip. Given this, we can expect the number of cores per chip to start doubling every so often.
As an example, I started writing this book on a 4-year-old dual-core laptop, and at the time of this writing I’m as excited as an expectant parent awaiting the arrival of my recently ordered quad-core notebook. However, excited as I am, it’s the depressing truth that most software written today doesn’t know how to use that many cores effectively.
Up to this point, developers have been better off avoiding the use of software concurrency primitives like threads because they come with many headaches such as deadlocks, convoys, and livelocks, just to name a few. And even if threads were used by the average developer, it was most likely to work around limitations in technologies such as the single-threaded nature of user interfaces on Windows.
Today, we can no longer ignore the importance of structuring our code so that it can start taking advantage of multiple cores. Threads, being the lowest-level primitive to introduce concurrency in programs, are no longer sufficient to deal with this alone. What we need instead are higher-order primitives that open up for fine-grained concurrency: tiny bits and pieces of execution that can be done in parallel if the hardware permits it.
Over the years, many approaches to parallel programming have emerged:
- Immutability is not a technology by itself, but rather a design and coding style focusing on eliminating shared writable mutable state. If modification of data is not permitted, there’s obviously no need to protect it against simultaneous modification. If data needs to be modified, new copies are made instead. The functional programming paradigm stimulates this style, and it’s the default in F#.
- Software transactional memory (STM) preaches exactly the opposite of immutability. Shared writable access is permitted, but mishaps, causing the data to become inconsistent, are dealt with through transactional semantics. This allows software to continue to be written in imperative style (with little additional language surface) but requires support from either the hardware or the runtime. STM is largely a research topic at this point.
- Side-effect-free programming is like immutability in a wider context; even simple tasks like input/output are prevented unless they’re made explicit through the type system. Haskell is such a language, enforcing this strictness on the developer. However, even without strict language support, a style of side-effect-free development can work. For example, filters and other clauses in LINQ queries are typically free of side effects, allowing parallelization.
- Asynchronous programming allows nonblocking calls to be made (for example, when making web requests), scheduling a piece of code (referred to as a continuation) to be called back when the call completes. Right from the start of the .NET Framework, there’s been support for this programming style, but the manual wiring left up to the developer has been quite cumbersome. New features like F# asynchronous workflows hide this complexity.
These styles have obviously led to the creation of libraries, runtime extensions, and language features supporting their active use. The order in which I mention the nature of those developer tools is quite important. In most cases, it’s too early for language designers to make a commitment to putting constructs in the language in support of one particular approach to concurrency. While concurrency experts figure out the best angle of attack to the problem, the language can keep itself free from potentially short-lived constructs.
This said, since the release of C# 3.0, there are plenty of language constructs library writers can piggyback on to provide a more-or-less natural integration with the existing language when trying out new approaches. A good example are the new .NET 4.0 System.Threading enhancements:
- Task Parallel Library (TPL) is the name for a set of primitives that allow scheduling of lightweight tasks that can be run in parallel. Such tasks can either produce values-in which case, they’re often called futures-or not. Note that tasks do not map to threads in a one-on-one fashion; a user mode scheduler is used to reuse a pool of threads, to avoid costly kernel mode transitions. Use of tasks is greatly simplified by the use of lambda expressions, and even parallel control structures like loops have been built out of this:
Parallel.For(1, 10, i => {
// perform computation
});
- Coordination Data Structures (CDS) are the building blocks for creating parallel algorithms, including rich concurrency-safe collection types. Other primitives offered by CDS include lightweight waits, locks, and events. Large parts of the user mode scheduler used by TPL are based on those structures, but they’re also readily available for direct use by developers.
- Parallel LINQ (PLINQ) is a form of data parallelism, in contrast to TPL’s task parallelism. In-memory queries written using LINQ expressions are ideal candidates for parallelization. Assume you’re applying a filter (with the where clause) to a million records; there’s nothing that prevents the runtime to be smart about the execution and run chunks of the filtering task on different cores. PLINQ exactly does that and again with minimal impact to the way code is written:
var res = from person in whitePages.AsParallel()
where person.City == “Seattle”
select person;
Readers interested in parallel programming-something that will only gain in importance over the years to come-are strongly encouraged to take a look at various approaches that have been researched. The .NET 4.0 System.Threading facilities are a good starting point (and we explore those in Chapter 30, “Task Parallelism and Data Parallelism”), but technologies such as F# asynchronous workflows are worth checking out, too. Other good search engine keyword searches include the Concurrency Coordination Runtime (CCR), ConcRT, and the recently released incubation project Axum (formerly known as Maestro), which is a C#-like language with first-class concepts such as agents and domains for isolation of state.
Summary
In this chapter, we took a look at the trends that have influenced-and are expected to continue to influence in the foreseeable future-the C# language. After having been born as an object-oriented language to go with the .NET Framework’s initial release, more and more developer-convenient features have been added to C# (for example, to ease data access with LINQ and to bridge with dynamically typed code using the DLR’s infrastructure). But we’re not done with C# yet; a lot of important trends need to be addressed going forward, to simplify development of concurrent software, to make the platform a better place for meta-programming, and to accommodate for the trends in the field of modeling.
Loaded with this general understanding of the field, you’re ready to start looking at the practical development of C#-based applications in the subsequent chapters. Chapter 3 starts by looking at the installation of the .NET Framework and the spectrum of tools available to develop managed code applications with it, and you write your first bare-bones application.
